
[ Seminars ] [ Seminars on CD ROM ] [ Consulting ]
“... describes a problem which occurs over
and over again in our environment, and then describes the core of the solution
to that problem, in such a way that you can use this solution a million times
over, without ever doing it the same way twice” – Christopher
Alexander
This chapter introduces the important and yet
non-traditional “patterns” approach to program design.
[[ Much of the prose in this chapter still needs work, but the
examples all compile. Also, more patterns and examples are forthcoming
]]
Probably the most important step forward in object-oriented
design is the “design patterns” movement, chronicled in
Design Patterns, by Gamma,
Helm, Johnson & Vlissides (Addison-Wesley
1995).[25] That book shows 23 different
solutions to particular classes of problems. In this chapter, the basic concepts
of design patterns will be introduced along with examples. This should whet your
appetite to read Design Patterns (a source of what has now become an
essential, almost mandatory, vocabulary for OOP programmers).
The latter part of this chapter contains an example of the
design evolution process, starting with an initial solution and moving through
the logic and process of evolving the solution to more appropriate designs. The
program shown (a trash recycling simulation) has evolved over time, and you can
look at that evolution as a prototype for the way your own design can start as
an adequate solution to a particular problem and evolve into a flexible approach
to a class of
problems.
Initially, you can think of a pattern as an especially clever
and insightful way of solving a particular class of problems. That is, it looks
like a lot of people have worked out all the angles of a problem and have come
up with the most general, flexible solution for it. The problem could be one you
have seen and solved before, but your solution probably didn’t have the
kind of completeness you’ll see embodied in a pattern.
Although they’re called “design patterns,”
they really aren’t tied to the realm of design. A pattern seems to stand
apart from the traditional way of thinking about analysis, design, and
implementation. Instead, a pattern embodies a complete idea within a program,
and thus it can sometimes appear at the analysis phase or high-level design
phase. This is interesting because a pattern has a direct implementation in code
and so you might not expect it to show up before low-level design or
implementation (and in fact you might not realize that you need a particular
pattern until you get to those phases).
The basic concept of a pattern can also be seen as the basic
concept of program design: adding layers of
abstraction. Whenever you abstract
something you’re isolating particular details, and one of the most
compelling motivations behind this is to separate things that change from
things that stay the same. Another way to put this is that once you find
some part of your program that’s likely to change for one reason or
another, you’ll want to keep those changes from propagating other
modifications throughout your code. Not only does this make the code much
cheaper to maintain, but it also turns out that it is usually simpler to
understand (which results in lowered costs).
Often, the most difficult part of developing an elegant and
cheap-to-maintain design is in discovering what I call “the
vector of
change.” (Here, “vector” refers to the maximum gradient and
not a container class.) This means finding the most important thing that changes
in your system, or put another way, discovering where your greatest cost is.
Once you discover the vector of change, you have the focal point around which to
structure your design.
So the goal of design patterns is to isolate changes in your
code. If you look at it this way, you’ve been seeing some design patterns
already in this book. For example, inheritance could be
thought of as a design pattern (albeit one implemented by the compiler). It
allows you to express differences in behavior (that’s the thing that
changes) in objects that all have the same interface (that’s what stays
the same). Composition could also be considered a
pattern, since it allows you to change – dynamically or statically –
the objects that implement your class, and thus the way that class works.
Normally, however, features that are directly supported by a programming
language are not classified as design patterns.
You’ve also already seen another pattern that appears in
Design Patterns: the iterator. This is the
fundamental tool used in the design of the STL; it hides the particular
implementation of the container as you’re stepping through and selecting
the elements one by one. The iterator allows you to write generic code that
performs an operation on all of the elements in a range without regard to the
container that holds the range. Thus your generic code can be used with any
container that can produce
iterators.
Possibly the simplest design pattern is the
singleton, which is a way to provide one and only
one instance of an object:
//: C10:SingletonPattern.cpp
#include <iostream>
using namespace std;
class Singleton {
static Singleton s;
int i;
Singleton(int x) : i(x) { }
void operator=(Singleton&);
Singleton(const Singleton&);
public:
static Singleton& getHandle() {
return s;
}
int getValue() { return i; }
void setValue(int x) { i = x; }
};
Singleton Singleton::s(47);
int main() {
Singleton& s = Singleton::getHandle();
cout << s.getValue() << endl;
Singleton& s2 = Singleton::getHandle();
s2.setValue(9);
cout << s.getValue() << endl;}
///:~
The key to creating a singleton is to prevent the client
programmer from having any way to create an object except the ways you provide.
To do this, you must declare all
constructors as private,
and you must create at least one constructor to prevent the compiler from
synthesizing a default constructor
for you.
At this point, you decide how you’re going to create
your object. Here, it’s created statically, but you can also wait until
the client programmer asks for one and create it on demand. In any case, the
object should be stored privately. You provide access through public methods.
Here, getHandle( ) produces a reference to the Singleton
object. The rest of the interface (getValue( ) and
setValue( )) is the regular class interface.
Note that you aren’t restricted to creating only one
object. This technique easily supports the creation of a limited pool of
objects. In that situation, however, you can be confronted with the problem of
sharing objects in the pool. If this is an issue, you can create a solution
involving a check-out and check-in of the shared objects.
Any static member object inside a class is an expression of
singleton: one and only one will be made. So in a sense, the language has direct
support for the idea; we certainly use it on a regular basis. However,
there’s a problem associated with static objects (member or not), and
that’s the order of initialization, as described in Volume 1 of this book.
If one static object depends on another, it’s important that the order of
initialization proceed correctly.
In Volume 1, you were shown how a static object defined inside
a function can be used to control initialization order. This delays the
initialization of the object until the first time the function is called. If the
function returns a reference to the static object, it gives you the effect of a
singleton while removing much of the worry of static initialization. For
example, suppose you want to create a logfile upon the first call to a function
which returns a reference to that logfile. This header file will do the
trick:
//: C10:LogFile.h
#ifndef LOGFILE_H
#define LOGFILE_H
#include <fstream>
inline std::ofstream& logfile() {
static std::ofstream log("Logfile.log");
return log;
}#endif // LOGFILE_H
///:~
The implementation must not be inlined, because that
would mean that the whole function, including the static object definition
within, could be duplicated in any translation unit where it’s included,
and you’d end up with multiple copies of the static object. This would
most certainly foil the attempts to control the order of initialization (but
potentially in a very subtle and hard-to-detect fashion). So the implementation
must be separate:
//: C10:LogFile.cpp {O}
#include "LogFile.h"
std::ofstream& logfile() {
static std::ofstream log("Logfile.log");
return log;}
///:~
Now the log object will not be initialized until the
first time logfile( ) is called. So if you use the function in one
file:
//: C10:UseLog1.h
#ifndef USELOG1_H
#define USELOG1_H
void f();
#endif // USELOG1_H ///:~
//: C10:UseLog1.cpp {O}
#include "UseLog1.h"
#include "LogFile.h"
void f() {
logfile() << __FILE__ << std::endl;}
///:~
And again in another file:
//: C10:UseLog2.cpp
//{L} UseLog1 LogFile
#include "UseLog1.h"
#include "LogFile.h"
using namespace std;
void g() {
logfile() << __FILE__ << endl;
}
int main() {
f();
g();}
///:~
Then the log object doesn’t get created until the
first call to f( ).
You can easily combine the creation of the static object
inside a member function with the singleton class. SingletonPattern.cpp
can be modified to use this approach:
//: C10:SingletonPattern2.cpp
#include <iostream>
using namespace std;
class Singleton {
int i;
Singleton(int x) : i(x) { }
void operator=(Singleton&);
Singleton(const Singleton&);
public:
static Singleton& getHandle() {
static Singleton s(47);
return s;
}
int getValue() { return i; }
void setValue(int x) { i = x; }
};
int main() {
Singleton& s = Singleton::getHandle();
cout << s.getValue() << endl;
Singleton& s2 = Singleton::getHandle();
s2.setValue(9);
cout << s.getValue() << endl;}
///:~
An especially interesting case is if two of these singletons
depend on each other, like this:
//: C10:FunctionStaticSingleton.cpp
class Singleton1 {
Singleton1() {}
public:
static Singleton1& ref() {
static Singleton1 single;
return single;
}
};
class Singleton2 {
Singleton1& s1;
Singleton2(Singleton1& s) : s1(s) {}
public:
static Singleton2& ref() {
static Singleton2 single(Singleton1::ref());
return single;
}
Singleton1& f() { return s1; }
};
int main() {
Singleton1& s1 = Singleton2::ref().f();}
///:~
When Singleton2::ref( ) is called, it causes its
sole Singleton2 object to be created. In the process of this creation,
Singleton1::ref( ) is called, and that causes the sole
Singleton1 object to be created. Because this technique doesn’t
rely on the order of linking or loading, the programmer has much better control
over initialization, leading to less problems.
The Design Patterns book discusses 23 different
patterns, classified under three purposes (all of which revolve around the
particular aspect that can vary). The three purposes are:
The Design
Patterns book has a section on each of its 23 patterns along with one or
more examples for each, typically in C++ but sometimes in Smalltalk. This book
will not repeat all the details of the patterns shown in Design Patterns
since that book stands on its own and should be studied separately. The catalog
and examples provided here are intended to rapidly give you a grasp of the
patterns, so you can get a decent feel for what patterns are about and why they
are so important.
[[ Describe different form of categorization, based on what
you want to accomplish rather than the way the patterns look. More categories,
but should result in easier-to-understand, faster selection
]]]
How things have gotten confused; conflicting pattern
descriptions, naïve “patterns,” patterns are not trivial nor
are they represented by features that are built into the language, nor are they
things that you do almost all the time. Constructors and destructors, for
example, could be called the “guaranteed initialization and cleanup design
pattern.” This is an important and essential idea, but it’s built
into the language.
Another example comes from various forms of aggregation.
Aggregation is a completely fundamental principle in object-oriented
programming: you make objects out of other objects [[ make reference to basic
tenets of OO ]]. Yet sometimes this idea is classified as a pattern, which tends
to confuse the issue. This is unfortunate because it pollutes the idea of the
design pattern and suggest that anything that surprises you the first time you
see it should be a design pattern.
Another misguided example is found in the Java language; the
designers of the “JavaBeans” specification decided to refer to a
simple naming convention as a design pattern (you say getInfo( ) for
a member function that returns an Info property and
setInfo( ) for one that changes the internal Info property;
the use of the “get” and “set” strings is what they
decided constituted calling it a design
pattern).
You’ll often find that messy code can be cleaned up by
putting it inside a class. This is more than fastidiousness – if nothing
else, it aids readability and therefore maintainability, and it can often lead
to reusability.
Simple Veneer (façade, Adapter (existing system),
Bridge (designed in),
Hiding types (polymorphism, iterators, proxy)
When you discover that you need to add new types to a system,
the most sensible first step to take is to use polymorphism to create a common
interface to those new types. This separates the rest of the code in your system
from the knowledge of the specific types that you are adding. New types may be
added without disturbing existing code ... or so it seems. At first it would
appear that the only place you need to change the code in such a design is the
place where you inherit a new type, but this is not quite true. You must still
create an object of your new type, and at the point of creation you must specify
the exact constructor to use. Thus, if the code that creates objects is
distributed throughout your application, you have the same problem when adding
new types – you must still chase down all the points of your code where
type matters. It happens to be the creation of the type that matters in
this case rather than the use of the type (which is taken care of by
polymorphism), but the effect is the same: adding a new type can cause
problems.
The solution is to force the creation of objects to occur
through a common factory rather than to allow the creational code to be
spread throughout your system. If all the code in your program must go through
this factory whenever it needs to create one of your objects, then all you must
do when you add a new object is to modify the factory.
Since every object-oriented program creates objects, and since
it’s very likely you will extend your program by adding new types, I
suspect that factories may be the most universally useful kinds of design
patterns.
As an example, let’s revisit the Shape system.
One approach is to make the factory a static method of the base
class:
//: C10:ShapeFactory1.cpp
#include "../purge.h"
#include <iostream>
#include <string>
#include <exception>
#include <vector>
using namespace std;
class Shape {
public:
virtual void draw() = 0;
virtual void erase() = 0;
virtual ~Shape() {}
class BadShapeCreation : public exception {
string reason;
public:
BadShapeCreation(string type) {
reason = "Cannot create type " + type;
}
const char *what() const {
return reason.c_str();
}
};
static Shape* factory(string type)
throw(BadShapeCreation);
};
class Circle : public Shape {
Circle() {} // Private constructor
friend class Shape;
public:
void draw() { cout << "Circle::draw\n"; }
void erase() { cout << "Circle::erase\n"; }
~Circle() { cout << "Circle::~Circle\n"; }
};
class Square : public Shape {
Square() {}
friend class Shape;
public:
void draw() { cout << "Square::draw\n"; }
void erase() { cout << "Square::erase\n"; }
~Square() { cout << "Square::~Square\n"; }
};
Shape* Shape::factory(string type)
throw(Shape::BadShapeCreation) {
if(type == "Circle") return new Circle;
if(type == "Square") return new Square;
throw BadShapeCreation(type);
}
char* shlist[] = { "Circle", "Square", "Square",
"Circle", "Circle", "Circle", "Square", "" };
int main() {
vector<Shape*> shapes;
try {
for(char** cp = shlist; **cp; cp++)
shapes.push_back(Shape::factory(*cp));
} catch(Shape::BadShapeCreation e) {
cout << e.what() << endl;
return 1;
}
for(int i = 0; i < shapes.size(); i++) {
shapes[i]->draw();
shapes[i]->erase();
}
purge(shapes);}
///:~
The factory( ) takes an argument that allows it to
determine what type of Shape to create; it happens to be a string
in this case but it could be any set of data. The factory( ) is now
the only other code in the system that needs to be changed when a new type of
Shape is added (the initialization data for the objects will presumably
come from somewhere outside the system, and not be a hard-coded array as in the
above example).
To ensure that the creation can only happen in the
factory( ), the constructors for the specific types of Shape
are made private, and Shape is declared a friend so that
factory( ) has access to the constructors (you could also declare
only Shape::factory( ) to be a friend, but it seems
reasonably harmless to declare the entire base class as a
friend).
The static factory( ) method in the previous
example forces all the creation operations to be focused in one spot, to
that’s the only place you need to change the code. This is certainly a
reasonable solution, as it throws a box around the process of creating objects.
However, the Design Patterns book emphasizes that the reason for the
Factory Method pattern is so that different types of factories can be
subclassed from the basic factory (the above design is mentioned as a special
case). However, the book does not provide an example, but instead just repeats
the example used for the Abstract Factory. Here is
ShapeFactory1.cpp modified so the factory methods are in a separate class
as virtual functions:
//: C10:ShapeFactory2.cpp
// Polymorphic factory methods
#include "../purge.h"
#include <iostream>
#include <string>
#include <exception>
#include <vector>
#include <map>
using namespace std;
class Shape {
public:
virtual void draw() = 0;
virtual void erase() = 0;
virtual ~Shape() {}
};
class ShapeFactory {
virtual Shape* create() = 0;
static map<string, ShapeFactory*> factories;
public:
virtual ~ShapeFactory() {}
friend class ShapeFactoryInizializer;
class BadShapeCreation : public exception {
string reason;
public:
BadShapeCreation(string type) {
reason = "Cannot create type " + type;
}
const char *what() const {
return reason.c_str();
}
};
static Shape*
createShape(string id) throw(BadShapeCreation){
if(factories.find(id) != factories.end())
return factories[id]->create();
else
throw BadShapeCreation(id);
}
};
// Define the static object:
map<string, ShapeFactory*>
ShapeFactory::factories;
class Circle : public Shape {
Circle() {} // Private constructor
public:
void draw() { cout << "Circle::draw\n"; }
void erase() { cout << "Circle::erase\n"; }
~Circle() { cout << "Circle::~Circle\n"; }
class Factory;
friend class Factory;
class Factory : public ShapeFactory {
public:
Shape* create() { return new Circle; }
};
};
class Square : public Shape {
Square() {}
public:
void draw() { cout << "Square::draw\n"; }
void erase() { cout << "Square::erase\n"; }
~Square() { cout << "Square::~Square\n"; }
class Factory;
friend class Factory;
class Factory : public ShapeFactory {
public:
Shape* create() { return new Square; }
};
};
// Singleton to initialize the ShapeFactory:
class ShapeFactoryInizializer {
static ShapeFactoryInizializer si;
ShapeFactoryInizializer() {
ShapeFactory::factories["Circle"] =
new Circle::Factory;
ShapeFactory::factories["Square"] =
new Square::Factory;
}
};
// Static member definition:
ShapeFactoryInizializer
ShapeFactoryInizializer::si;
char* shlist[] = { "Circle", "Square", "Square",
"Circle", "Circle", "Circle", "Square", "" };
int main() {
vector<Shape*> shapes;
try {
for(char** cp = shlist; **cp; cp++)
shapes.push_back(
ShapeFactory::createShape(*cp));
} catch(ShapeFactory::BadShapeCreation e) {
cout << e.what() << endl;
return 1;
}
for(int i = 0; i < shapes.size(); i++) {
shapes[i]->draw();
shapes[i]->erase();
}
purge(shapes);}
///:~
Now the factory method appears in its own class,
ShapeFactory, as the virtual create( ). This is a
private method which means it cannot be called directly, but it can be
overridden. The subclasses of Shape must each create their own subclasses
of ShapeFactory and override the create( ) method to create
an object of their own type. The actual creation of shapes is performed by
calling ShapeFactory::createShape( ), which is a static method that
uses the map in ShapeFactory to find the appropriate factory
object based on an identifier that you pass it. The factory is immediately used
to create the shape object, but you could imagine a more complex problem where
the appropriate factory object is returned and then used by the caller to create
an object in a more sophisticated way. However, it seems that much of the time
you don’t need the intricacies of the polymorphic factory method, and a
single static method in the base class (as shown in ShapeFactory1.cpp)
will work fine.
Notice that the ShapeFactory must be initialized by
loading its map with factory objects, which takes place in the singleton
ShapeFactoryInizializer. So to add a new type to this design you must
inherit the type, create a factory, and modify ShapeFactoryInizializer so
that an instance of your factory is inserted in the map. This extra complexity
again suggests the use of a static factory method if you don’t need
to create individual factory
objects.
The Abstract Factory pattern looks like the factory
objects we’ve seen previously, with not one but several factory methods.
Each of the factory methods creates a different kind of object. The idea is that
at the point of creation of the factory object, you decide how all the objects
created by that factory will be used. The example given in Design
Patterns implements portability across various graphical user interfaces
(GUIs): you create a factory object appropriate to the GUI that you’re
working with, and from then on when you ask it for a menu, button, slider, etc.
it will automatically create the appropriate version of that item for the GUI.
Thus you’re able to isolate, in one place, the effect of changing from one
GUI to another.
As another example suppose you are creating a general-purpose
gaming environment and you want to be able to support different types of games.
Here’s how it might look using an abstract factory:
//: C10:AbstractFactory.cpp
// A gaming environment
#include <iostream>
using namespace std;
class Obstacle {
public:
virtual void action() = 0;
};
class Player {
public:
virtual void interactWith(Obstacle*) = 0;
};
class Kitty: public Player {
virtual void interactWith(Obstacle* ob) {
cout << "Kitty has encountered a ";
ob->action();
}
};
class KungFuGuy: public Player {
virtual void interactWith(Obstacle* ob) {
cout << "KungFuGuy now battles against a ";
ob->action();
}
};
class Puzzle: public Obstacle {
public:
void action() { cout << "Puzzle\n"; }
};
class NastyWeapon: public Obstacle {
public:
void action() { cout << "NastyWeapon\n"; }
};
// The abstract factory:
class GameElementFactory {
public:
virtual Player* makePlayer() = 0;
virtual Obstacle* makeObstacle() = 0;
};
// Concrete factories:
class KittiesAndPuzzles :
public GameElementFactory {
public:
virtual Player* makePlayer() {
return new Kitty;
}
virtual Obstacle* makeObstacle() {
return new Puzzle;
}
};
class KillAndDismember :
public GameElementFactory {
public:
virtual Player* makePlayer() {
return new KungFuGuy;
}
virtual Obstacle* makeObstacle() {
return new NastyWeapon;
}
};
class GameEnvironment {
GameElementFactory* gef;
Player* p;
Obstacle* ob;
public:
GameEnvironment(GameElementFactory* factory) :
gef(factory), p(factory->makePlayer()),
ob(factory->makeObstacle()) {}
void play() {
p->interactWith(ob);
}
~GameEnvironment() {
delete p;
delete ob;
delete gef;
}
};
int main() {
GameEnvironment
g1(new KittiesAndPuzzles),
g2(new KillAndDismember);
g1.play();
g2.play();}
///:~
In this environment, Player objects interact with
Obstacle objects, but there are different types of players and obstacles
depending on what kind of game you’re playing. You determine the kind of
game by choosing a particular GameElementFactory, and then the
GameEnvironment controls the setup and play of the game. In this example,
the setup and play is very simple, but those activities (the initial
conditions and the state change) can determine much of the
game’s outcome. Here, GameEnvironment is not designed to be
inherited, although it could very possibly make sense to do that.
This also contains examples of Double Dispatching and
the Factory Method, both of which will be explained
later.
Show simpler version of virtual constructor scheme,
letting the user create the object with new. Probably make constructor for
objects private and use a maker function to force all objects on the
heap.
One of the primary goals of using a factory is so that
you can
organize your code so you don’t have to select an exact type of
constructor when creating an object. That is, you can say, “I don’t
know precisely what type of object you are, but here’s the information:
Create yourself.”
In addition, during a constructor call the virtual mechanism
does not operate (early binding occurs). Sometimes this is awkward. For example,
in the Shape program it seems logical that inside the constructor for a
Shape object, you would want to set everything up and then
draw( ) the Shape. draw( ) should be a virtual
function, a message to the Shape that it should draw itself
appropriately, depending on whether it is a circle, square, line, and so on.
However, this doesn’t work inside the constructor, for the reasons given
in Chapter XX: Virtual functions
resolve to the “local” function bodies when called in
constructors.
If you want to be able to call a virtual function inside the
constructor and have it do the right thing, you must use a technique to
simulate a virtual constructor (which is a variation of the Factory
Method). This is a conundrum. Remember the idea of a virtual function is
that you send a message to an object and let the object figure out the right
thing to do. But a constructor builds an object. So a virtual constructor would
be like saying, “I don’t know exactly what type of object you are,
but build yourself anyway.” In an ordinary constructor, the compiler must
know which VTABLE address to bind to the
VPTR, and if it existed, a virtual constructor
couldn’t do this because it doesn’t know all the type information at
compile-time. It makes sense that a constructor can’t be virtual because
it is the one function that absolutely must know everything about the type of
the object.
And yet there are times when you want something approximating
the behavior of a virtual constructor.
In the Shape example, it would be nice to hand the
Shape constructor some specific information in the argument list and let
the constructor create a specific type of Shape (a Circle,
Square) with no further intervention. Ordinarily, you’d have to
make an explicit call to the Circle, Square constructor
yourself.
Coplien[26]
calls his solution to this problem “envelope and letter classes.”
The “envelope” class is the base class, a shell that contains a
pointer to an object of the base class. The constructor for the
“envelope” determines (at runtime, when the constructor is called,
not at compile-time, when the type checking is normally done) what specific type
to make, then creates an object of that specific type (on the heap) and assigns
the object to its pointer. All the function calls are then handled by the base
class through its pointer. So the base class is acting as a proxy for the
derived class:
//: C10:VirtualConstructor.cpp
#include <iostream>
#include <string>
#include <exception>
#include <vector>
using namespace std;
class Shape {
Shape* s;
// Prevent copy-construction & operator=
Shape(Shape&);
Shape operator=(Shape&);
protected:
Shape() { s = 0; };
public:
virtual void draw() { s->draw(); }
virtual void erase() { s->erase(); }
virtual void test() { s->test(); };
virtual ~Shape() {
cout << "~Shape\n";
if(s) {
cout << "Making virtual call: ";
s->erase(); // Virtual call
}
cout << "delete s: ";
delete s; // The polymorphic deletion
}
class BadShapeCreation : public exception {
string reason;
public:
BadShapeCreation(string type) {
reason = "Cannot create type " + type;
}
const char *what() const {
return reason.c_str();
}
};
Shape(string type) throw(BadShapeCreation);
};
class Circle : public Shape {
Circle(Circle&);
Circle operator=(Circle&);
Circle() {} // Private constructor
friend class Shape;
public:
void draw() { cout << "Circle::draw\n"; }
void erase() { cout << "Circle::erase\n"; }
void test() { draw(); }
~Circle() { cout << "Circle::~Circle\n"; }
};
class Square : public Shape {
Square(Square&);
Square operator=(Square&);
Square() {}
friend class Shape;
public:
void draw() { cout << "Square::draw\n"; }
void erase() { cout << "Square::erase\n"; }
void test() { draw(); }
~Square() { cout << "Square::~Square\n"; }
};
Shape::Shape(string type)
throw(Shape::BadShapeCreation) {
if(type == "Circle")
s = new Circle;
else if(type == "Square")
s = new Square;
else throw BadShapeCreation(type);
draw(); // Virtual call in the constructor
}
char* shlist[] = { "Circle", "Square", "Square",
"Circle", "Circle", "Circle", "Square", "" };
int main() {
vector<Shape*> shapes;
cout << "virtual constructor calls:" << endl;
try {
for(char** cp = shlist; **cp; cp++)
shapes.push_back(new Shape(*cp));
} catch(Shape::BadShapeCreation e) {
cout << e.what() << endl;
return 1;
}
for(int i = 0; i < shapes.size(); i++) {
shapes[i]->draw();
cout << "test\n";
shapes[i]->test();
cout << "end test\n";
shapes[i]->erase();
}
Shape c("Circle"); // Create on the stack
cout << "destructor calls:" << endl;
for(int j = 0; j < shapes.size(); j++) {
delete shapes[j];
cout << "\n------------\n";
}}
///:~
The base class Shape contains a pointer to an object of
type Shape as its only data member. When you build a “virtual
constructor” scheme, you must exercise special care to ensure this pointer
is always initialized to a live object.
Each time you derive a new subtype from Shape, you must
go back and add the creation for that type in one place, inside the
“virtual constructor” in the Shape base class. This is not
too onerous a task, but the disadvantage is you now have a dependency between
the Shape class and all classes derived from it (a reasonable trade-off,
it seems). Also, because it is a proxy, the base-class interface is truly the
only thing the user sees.
In this example, the information you must hand the virtual
constructor about what type to create is very explicit: It’s a
string that names the type. However, your scheme may use other
information – for example, in a parser the output of the scanner may be
handed to the virtual constructor, which then uses that information to determine
which token to create.
The virtual constructor Shape(type) can only be
declared inside the class; it cannot be defined until after all the derived
classes have been declared. However, the default
constructor can be defined inside
class Shape, but it should be made protected so temporary
Shape objects cannot be created. This default constructor is only called
by the constructors of derived-class objects. You are forced to explicitly
create a default constructor because the compiler will create one for you
automatically only if there are no constructors defined. Because you must
define Shape(type), you must also define Shape( ).
The default constructor in this scheme has at least one very
important chore – it must set the value of the s pointer to zero.
This sounds strange at first, but remember that the default constructor will be
called as part of the construction of the actual object – in
Coplien’s terms, the “letter,” not the “envelope.”
However, the “letter” is derived from the “envelope,” so
it also inherits the data member s. In the “envelope,”
s is important because it points to the actual object, but in the
“letter,” s is simply excess baggage. Even excess baggage
should be initialized, however, and if s is not set to zero by the
default constructor called for the “letter,” bad things happen (as
you’ll see later).
The virtual constructor takes as its argument information that
completely determines the type of the object. Notice, though, that this type
information isn’t read and acted upon until runtime, whereas normally the
compiler must know the exact type at compile-time (one other reason this system
effectively imitates virtual constructors).
Inside the virtual constructor there’s a switch
statement that uses the argument to construct the actual (“letter”)
object, which is then assigned to the pointer inside the “envelope.”
At that point, the construction of the “letter” has been completed,
so any virtual calls will be properly directed.
As an example, consider the call to draw( ) inside
the virtual constructor. If you trace this call (either by hand or with a
debugger), you can see that it starts in the draw( ) function in the
base class, Shape. This function calls draw( ) for the
“envelope” s pointer to its “letter.” All types
derived from Shape share the same interface, so this virtual call is
properly executed, even though it seems to be in the constructor. (Actually, the
constructor for the “letter” has already completed.) As long as all
virtual calls in the base class simply make calls to identical virtual function
through the pointer to the “letter,” the system operates
properly.
To understand how it works, consider the code in
main( ). To fill the vector shapes, “virtual
constructor” calls are made to Shape. Ordinarily in a situation
like this, you would call the constructor for the actual type, and the VPTR for
that type would be installed in the object. Here, however, the VPTR used in each
case is the one for Shape, not the one for the specific Circle,
Square, or Triangle.
In the for loop where the draw( ) and
erase( ) functions are called for each Shape, the virtual
function call resolves, through the VPTR, to the corresponding type. However,
this is Shape in each case. In fact, you might wonder why
draw( ) and erase( ) were made virtual at all.
The reason shows up in the next step: The base-class version of
draw( ) makes a call, through the “letter” pointer
s, to the virtual function draw( ) for the
“letter.” This time the call resolves to the actual type of the
object, not just the base class Shape. Thus the runtime cost of using
virtual constructors is one more virtual call every time you make a virtual
function call.
In order to create any function that is overridden, such as
draw( ), erase( ) or test( ), you must proxy
all calls to the s pointer in the base class implementation, as shown
above. This is because, when the call is made, the call to the envelope’s
member function will resolve as being to Shape, and not to a derived type
of Shape. Only when you make the proxy call to s will the virtual
behavior take place. In main( ), you can see that everything works
correctly, even when calls are made inside constructors and
destructors.
The activities of destruction in this scheme are also tricky.
To understand, let’s verbally walk through what happens when you call
delete for a pointer to a Shape object – specifically, a
Square – created on the heap. (This is more complicated than an
object created on the stack.) This will be a delete through the
polymorphic interface, as in the statement delete shapes[i] in
main( ).
The type of the pointer shapes[i] is of the base class
Shape, so the compiler makes the call through Shape. Normally, you
might say that it’s a virtual call, so Square’s destructor
will be called. But with the virtual constructor scheme, the compiler is
creating actual Shape objects, even though the constructor initializes
the letter pointer to a specific type of Shape. The virtual mechanism
is used, but the VPTR inside the Shape object is
Shape’s VPTR, not Square’s. This resolves to
Shape’s destructor, which calls delete for the letter
pointer s, which actually points to a Square object. This is again
a virtual call, but this time it resolves to Square’s
destructor.
With a destructor, however, C++ guarantees, via the compiler,
that all destructors in the hierarchy are called. Square’s
destructor is called first, followed by any intermediate destructors, in order,
until finally the base-class destructor is called. This base-class destructor
has code that says delete s. When this destructor was called originally,
it was for the “envelope” s, but now it’s for the
“letter” s, which is there because the “letter”
was inherited from the “envelope,” and not because it contains
anything. So this call to delete should do nothing.
The solution to the problem is to make the
“letter” s pointer zero. Then when the “letter”
base-class destructor is called, you get delete 0, which by definition
does nothing. Because the default constructor is protected, it will be called
only during the construction of a “letter,” so that’s
the only situation where s is set to zero.
Your most common tool for hiding construction will probably be
ordinary factory methods rather than the more complex approaches. The idea of
adding new types with minimal effect on the rest of the system will be further
explored later in this chapter.
Like the other forms of callback, this contains a hook point
where you can change code. The difference is in the observer’s completely
dynamic nature. It is often used for the specific case of changes based on other
object’s change of state, but is also the basis of event management.
Anytime you want to decouple the source of the call from the called code in a
completely dynamic way.
The observer
pattern solves a fairly common problem: What if a group of objects needs to
update themselves when some other object changes state? This can be seen in the
“model-view” aspect of Smalltalk’s MVC
(model-view-controller), or the almost-equivalent “Document-View
Architecture.” Suppose that you have some data (the
“document”) and more than one view, say a plot and a textual view.
When you change the data, the two views must know to update themselves, and
that’s what the observer facilitates.
There are two types of objects used to implement the observer
pattern in the following code. The Observable
class keeps track of everybody who wants to be informed when a change happens,
whether the “state” has changed or not. When someone says “OK,
everybody should check and potentially update themselves,” the
Observable class performs this task by calling the
notifyObservers( ) member function for each
observer on the list. The notifyObservers( ) member function is part
of the base class Observable.
There are actually two “things that change” in the
observer pattern: the quantity of observing objects and the way an update
occurs. That is, the observer pattern allows you to modify both of these without
affecting the surrounding code.
There are a number of ways to implement the observer pattern,
but the code shown here will create a framework from which you can build your
own observer code, following the example. First, this interface describes what
an observer looks like:
//: C10:Observer.h
// The Observer interface
#ifndef OBSERVER_H
#define OBSERVER_H
class Observable;
class Argument {};
class Observer {
public:
// Called by the observed object, whenever
// the observed object is changed:
virtual void
update(Observable* o, Argument * arg) = 0;
};#endif // OBSERVER_H
///:~
Since Observer interacts with Observable in this
approach, Observable must be declared first. In addition, the
Argument class is empty and only acts as a base class for any type of
argument you wish to pass during an update. If you want, you can simply pass the
extra argument as a void*; you’ll have to downcast in either case
but some folks find void* objectionable.
Observer is an “interface” class that only
has one member function, update( ). This function is called by the
object that’s being observed, when that object decides its time to update
all it’s observers. The arguments are optional; you could have an
update( ) with no arguments and that would still fit the observer
pattern; however this is more general – it allows the observed object to
pass the object that caused the update (since an Observer may be
registered with more than one observed object) and any extra information if
that’s helpful, rather than forcing the Observer object to hunt
around to see who is updating and to fetch any other information it
needs.
The “observed object” that decides when and how to
do the updating will be called the Observable:
//: C10:Observable.h
// The Observable class
#ifndef OBSERVABLE_H
#define OBSERVABLE_H
#include "Observer.h"
#include <set>
class Observable {
bool changed;
std::set<Observer*> observers;
protected:
virtual void setChanged() { changed = true; }
virtual void clearChanged(){ changed = false; }
public:
virtual void addObserver(Observer& o) {
observers.insert(&o);
}
virtual void deleteObserver(Observer& o) {
observers.erase(&o);
}
virtual void deleteObservers() {
observers.clear();
}
virtual int countObservers() {
return observers.size();
}
virtual bool hasChanged() { return changed; }
// If this object has changed, notify all
// of its observers:
virtual void notifyObservers(Argument* arg=0) {
if(!hasChanged()) return;
clearChanged(); // Not "changed" anymore
std::set<Observer*>::iterator it;
for(it = observers.begin();
it != observers.end(); it++)
(*it)->update(this, arg);
}
};#endif // OBSERVABLE_H
///:~
Again, the design here is more elaborate than is necessary; as
long as there’s a way to register an Observer with an
Observable and for the Observable to update its Observers,
the set of member functions doesn’t matter. However, this design is
intended to be reusable (it was lifted from the design used in the Java standard
library). As mentioned elsewhere in the book, there is no support for
multithreading in the Standard C++ libraries, so this design would need to be
modified in a multithreaded environment.
Observable has a flag to indicate whether it’s
been changed. In a simpler design, there would be no flag; if something
happened, everyone would be notified. The flag allows you to wait, and only
notify the Observers when you decide the time is right. Notice, however,
that the control of the flag’s state is protected, so that only an
inheritor can decide what constitutes a change, and not the end user of the
resulting derived Observer class.
The collection of Observer objects is kept in a
set<Observer*> to prevent duplicates; the set
insert( ), erase( ), clear( ) and
size( ) functions are exposed to allow Observers to be added
and removed at any time, thus providing runtime flexibility.
Most of the work is done in notifyObservers( ). If
the changed flag has not been set, this does nothing. Otherwise, it first
clears the changed flag so repeated calls to
notifyObservers( ) won’t waste time. This is done before
notifying the observers in case the calls to update( ) do anything
that causes a change back to this Observable object. Then it moves
through the set and calls back to the update( ) member
function of each Observer.
At first it may appear that you can use an ordinary
Observable object to manage the updates. But this doesn’t work; to
get an effect, you must inherit from Observable and somewhere in
your derived-class code call setChanged( ).
This is the member function that sets the “changed” flag, which
means that when you call notifyObservers( )
all of the observers will, in fact, get notified. Where you call
setChanged( ) depends on the logic of your program.
Now we encounter a dilemma. An object that should notify its
observers about things that happen to it – events or changes in state
– might have more than one such item of interest. For example, if
you’re dealing with a graphical user interface (GUI) item – a
button, say – the items of interest might be the mouse clicked the button,
the mouse moved over the button, and (for some reason) the button changed its
color. So we’d like to be able to report all of these events to different
observers, each of which is interested in a different type of event.
The problem is that we would normally reach for multiple
inheritance in such a situation: “I’ll inherit from
Observable to deal with mouse clicks, and I’ll ... er ... inherit
from Observable to deal with mouse-overs, and, well, ... hmm, that
doesn’t work.”
Here’s a situation where we do actually need to (in
effect) upcast to more than one type, but in this case we need to provide
several different implementations of the same base type. The solution is
something I’ve lifted from Java, which takes C++’s nested class one
step further. Java has a built-in feature called inner classes, which
look like C++’s nested classes, but they do two other things:
[[ Insert the definition of
a closure ]]. So to implement the inner class idiom in C++, we must do these
things by hand. Here’s an example:
//: C10:InnerClassIdiom.cpp
// Example of the "inner class" idiom
#include <iostream>
#include <string>
using namespace std;
class Poingable {
public:
virtual void poing() = 0;
};
void callPoing(Poingable& p) {
p.poing();
}
class Bingable {
public:
virtual void bing() = 0;
};
void callBing(Bingable& b) {
b.bing();
}
class Outer {
string name;
// Define one inner class:
class Inner1;
friend class Outer::Inner1;
class Inner1 : public Poingable {
Outer* parent;
public:
Inner1(Outer* p) : parent(p) {}
void poing() {
cout << "poing called for "
<< parent->name << endl;
// Accesses data in the outer class object
}
} inner1;
// Define a second inner class:
class Inner2;
friend class Outer::Inner2;
class Inner2 : public Bingable {
Outer* parent;
public:
Inner2(Outer* p) : parent(p) {}
void bing() {
cout << "bing called for "
<< parent->name << endl;
}
} inner2;
public:
Outer(const string& nm) : name(nm),
inner1(this), inner2(this) {}
// Return reference to interfaces
// implemented by the inner classes:
operator Poingable&() { return inner1; }
operator Bingable&() { return inner2; }
};
int main() {
Outer x("Ping Pong");
// Like upcasting to multiple base types!:
callPoing(x);
callBing(x);}
///:~
The example begins with the Poingable and Bingable
interfaces, each of which contain a single member function. The services
provided by callPoing( ) and callBing( ) require that
the object they receive implement the Poingable and Bingable
interfaces, respectively, but they put no other requirements on that object
so as to maximize the flexibility of using callPoing( ) and
callBing( ). Note the lack of virtual destructors in either
interface – the intent is that you never perform object destruction via
the interface.
Outer contains some private data (name) and it
wishes to provide both a Poingable interface and a Bingable
interface so it can be used with callPoing( ) and
callBing( ). Of course, in this situation we could simply use
multiple inheritance. This example is just intended to show the simplest syntax
for the idiom; we’ll see a real use shortly. To provide a Poingable
object without inheriting Outer from Poingable, the inner class
idiom is used. First, the declaration class Inner says that, somewhere,
there is a nested class of this name. This allows the friend declaration
for the class, which follows. Finally, now that the nested class has been
granted access to all the private elements of Outer, the class can be
defined. Notice that it keeps a pointer to the Outer which created it,
and this pointer must be initialized in the constructor. Finally, the
poing( ) function from Poingable is implemented. The same
process occurs for the second inner class which implements Bingable. Each
inner class has a single private instance created, which is initialized
in the Outer constructor. By creating the member objects and returning
references to them, issues of object lifetime are eliminated.
Notice that both inner class definitions are private,
and in fact the client programmer doesn’t have any access to details of
the implementation, since the two access methods operator
Poingable&( ) and operator Bingable&( ) only return
a reference to the upcast interface, not to the object that implements it. In
fact, since the two inner classes are private, the client programmer
cannot even downcast to the implementation classes, thus providing complete
isolation between interface and implementation.
Just to push a point, I’ve taken the extra liberty here
of defining the automatic type conversion operators operator
Poingable&( ) and operator Bingable&( ). In
main( ), you can see that these actually allow a syntax that looks
like Outer is multiply inherited from Poingable and
Bingable. The difference is that the casts in this case are one way. You
can get the effect of an upcast to Poingable or Bingable, but you
cannot downcast back to an Outer. In the following example of observer,
you’ll see the more typical approach: you provide access to the inner
class objects using ordinary member functions, not automatic type conversion
operations.
Armed with the Observer and Observable header
files and the inner class idiom, we can look at an example of the observer
pattern:
//: C10:ObservedFlower.cpp
// Demonstration of "observer" pattern
#include "Observable.h"
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
using namespace std;
class Flower {
bool isOpen;
public:
Flower() : isOpen(false),
openNotifier(this), closeNotifier(this) {}
void open() { // Opens its petals
isOpen = true;
openNotifier.notifyObservers();
closeNotifier.open();
}
void close() { // Closes its petals
isOpen = false;
closeNotifier.notifyObservers();
openNotifier.close();
}
// Using the "inner class" idiom:
class OpenNotifier;
friend class Flower::OpenNotifier;
class OpenNotifier : public Observable {
Flower* parent;
bool alreadyOpen;
public:
OpenNotifier(Flower* f) : parent(f),
alreadyOpen(false) {}
void notifyObservers(Argument* arg=0) {
if(parent->isOpen && !alreadyOpen) {
setChanged();
Observable::notifyObservers();
alreadyOpen = true;
}
}
void close() { alreadyOpen = false; }
} openNotifier;
class CloseNotifier;
friend class Flower::CloseNotifier;
class CloseNotifier : public Observable {
Flower* parent;
bool alreadyClosed;
public:
CloseNotifier(Flower* f) : parent(f),
alreadyClosed(false) {}
void notifyObservers(Argument* arg=0) {
if(!parent->isOpen && !alreadyClosed) {
setChanged();
Observable::notifyObservers();
alreadyClosed = true;
}
}
void open() { alreadyClosed = false; }
} closeNotifier;
};
class Bee {
string name;
// An "inner class" for observing openings:
class OpenObserver;
friend class Bee::OpenObserver;
class OpenObserver : public Observer {
Bee* parent;
public:
OpenObserver(Bee* b) : parent(b) {}
void update(Observable*, Argument *) {
cout << "Bee " << parent->name
<< "'s breakfast time!\n";
}
} openObsrv;
// Another "inner class" for closings:
class CloseObserver;
friend class Bee::CloseObserver;
class CloseObserver : public Observer {
Bee* parent;
public:
CloseObserver(Bee* b) : parent(b) {}
void update(Observable*, Argument *) {
cout << "Bee " << parent->name
<< "'s bed time!\n";
}
} closeObsrv;
public:
Bee(string nm) : name(nm),
openObsrv(this), closeObsrv(this) {}
Observer& openObserver() { return openObsrv; }
Observer& closeObserver() { return closeObsrv;}
};
class Hummingbird {
string name;
class OpenObserver;
friend class Hummingbird::OpenObserver;
class OpenObserver : public Observer {
Hummingbird* parent;
public:
OpenObserver(Hummingbird* h) : parent(h) {}
void update(Observable*, Argument *) {
cout << "Hummingbird " << parent->name
<< "'s breakfast time!\n";
}
} openObsrv;
class CloseObserver;
friend class Hummingbird::CloseObserver;
class CloseObserver : public Observer {
Hummingbird* parent;
public:
CloseObserver(Hummingbird* h) : parent(h) {}
void update(Observable*, Argument *) {
cout << "Hummingbird " << parent->name
<< "'s bed time!\n";
}
} closeObsrv;
public:
Hummingbird(string nm) : name(nm),
openObsrv(this), closeObsrv(this) {}
Observer& openObserver() { return openObsrv; }
Observer& closeObserver() { return closeObsrv;}
};
int main() {
Flower f;
Bee ba("A"), bb("B");
Hummingbird ha("A"), hb("B");
f.openNotifier.addObserver(ha.openObserver());
f.openNotifier.addObserver(hb.openObserver());
f.openNotifier.addObserver(ba.openObserver());
f.openNotifier.addObserver(bb.openObserver());
f.closeNotifier.addObserver(ha.closeObserver());
f.closeNotifier.addObserver(hb.closeObserver());
f.closeNotifier.addObserver(ba.closeObserver());
f.closeNotifier.addObserver(bb.closeObserver());
// Hummingbird B decides to sleep in:
f.openNotifier.deleteObserver(hb.openObserver());
// Something changes that interests observers:
f.open();
f.open(); // It's already open, no change.
// Bee A doesn't want to go to bed:
f.closeNotifier.deleteObserver(
ba.closeObserver());
f.close();
f.close(); // It's already closed; no change
f.openNotifier.deleteObservers();
f.open();
f.close();}
///:~
The events of interest are that a Flower can open or
close. Because of the use of the inner class idiom, both these events can be
separately-observable phenomena. OpenNotifier and CloseNotifier
both inherit Observable, so they have access to setChanged( )
and can be handed to anything that needs an Observable. You’ll
notice that, contrary to InnerClassIdiom.cpp, the Observable
descendants are public. This is because some of their member functions
must be available to the client programmer. There’s nothing that says that
an inner class must be private; in InnerClassIdiom.cpp I was
simply following the design guideline “make things as private as
possible.” You could make the classes private and expose the
appropriate methods by proxy in Flower, but it wouldn’t gain
much.
The inner class idiom also comes in handy to define more than
one kind of Observer, in Bee and Hummingbird, since both
those classes may want to independently observe Flower openings and
closings. Notice how the inner class idiom provides something that has most of
the benefits of inheritance (the ability to access the private data in the outer
class, for example) without the same restrictions.
In main( ), you can see one of the prime benefits
of the observer pattern: the ability to change behavior at runtime by
dynamically registering and un-registering Observers with
Observables.
If you study the code above you’ll see that
OpenNotifier and CloseNotifier use the basic Observable
interface. This means that you could inherit other completely different
Observer classes; the only connection the Observers have with
Flowers is the Observer
interface.
When dealing with multiple types which are interacting, a
program can get particularly messy. For example, consider a system that parses
and executes mathematical expressions. You want to be able to say Number +
Number, Number * Number, etc., where Number is the base class
for a family of numerical objects. But when you say a + b, and you
don’t know the exact type of either a or b, so how can you
get them to interact properly?
The answer starts with something you probably don’t
think about: C++ performs only single dispatching. That is, if you are
performing an operation on more than one object whose type is unknown, C++ can
invoke the dynamic binding mechanism on only one of those types. This
doesn’t solve the problem, so you end up detecting some types manually and
effectively producing your own dynamic binding behavior.
The solution is called
multiple dispatching.
Remember that polymorphism can occur only via member function calls, so if you
want double dispatching to occur, there must be two member function calls: the
first to determine the first unknown type, and the second to determine the
second unknown type. With multiple dispatching, you must have a virtual call to
determine each of the types. Generally, you’ll set up a configuration such
that a single member function call produces more than one dynamic member
function call and thus determines more than one type in the process. To get this
effect, you need to work with more than one virtual function: you’ll need
a virtual function call for each dispatch. The virtual functions in the
following example are called compete( ) and eval( ), and
are both members of the same type. (In this case there will be only two
dispatches, which is referred to as
double dispatching). If you
are working with two different type hierarchies that are interacting, then
you’ll have to have a virtual call in each hierarchy.
Here’s an example of multiple dispatching:
//: C10:PaperScissorsRock.cpp
// Demonstration of multiple dispatching
#include "../purge.h"
#include <iostream>
#include <vector>
#include <algorithm>
#include <cstdlib>
#include <ctime>
using namespace std;
class Paper;
class Scissors;
class Rock;
enum Outcome { win, lose, draw };
ostream&
operator<<(ostream& os, const Outcome out) {
switch(out) {
default:
case win: return os << "win";
case lose: return os << "lose";
case draw: return os << "draw";
}
}
class Item {
public:
virtual Outcome compete(const Item*) = 0;
virtual Outcome eval(const Paper*) const = 0;
virtual Outcome eval(const Scissors*) const= 0;
virtual Outcome eval(const Rock*) const = 0;
virtual ostream& print(ostream& os) const = 0;
virtual ~Item() {}
friend ostream&
operator<<(ostream& os, const Item* it) {
return it->print(os);
}
};
class Paper : public Item {
public:
Outcome compete(const Item* it) {
return it->eval(this);
}
Outcome eval(const Paper*) const {
return draw;
}
Outcome eval(const Scissors*) const {
return win;
}
Outcome eval(const Rock*) const {
return lose;
}
ostream& print(ostream& os) const {
return os << "Paper ";
}
};
class Scissors : public Item {
public:
Outcome compete(const Item* it) {
return it->eval(this);
}
Outcome eval(const Paper*) const {
return lose;
}
Outcome eval(const Scissors*) const {
return draw;
}
Outcome eval(const Rock*) const {
return win;
}
ostream& print(ostream& os) const {
return os << "Scissors";
}
};
class Rock : public Item {
public:
Outcome compete(const Item* it) {
return it->eval(this);
}
Outcome eval(const Paper*) const {
return win;
}
Outcome eval(const Scissors*) const {
return lose;
}
Outcome eval(const Rock*) const {
return draw;
}
ostream& print(ostream& os) const {
return os << "Rock ";
}
};
struct ItemGen {
ItemGen() { srand(time(0)); }
Item* operator()() {
switch(rand() % 3) {
default:
case 0:
return new Scissors;
case 1:
return new Paper;
case 2:
return new Rock;
}
}
};
struct Compete {
Outcome operator()(Item* a, Item* b) {
cout << a << "\t" << b << "\t";
return a->compete(b);
}
};
int main() {
const int sz = 20;
vector<Item*> v(sz*2);
generate(v.begin(), v.end(), ItemGen());
transform(v.begin(), v.begin() + sz,
v.begin() + sz,
ostream_iterator<Outcome>(cout, "\n"),
Compete());
purge(v);}
///:~
The assumption is that you have a primary class hierarchy that
is fixed; perhaps it’s from another vendor and you can’t make
changes to that hierarchy. However, you’d like to add new polymorphic
methods to that hierarchy, which means that normally you’d have to add
something to the base class interface. So the dilemma is that you need to add
methods to the base class, but you can’t touch the base class. How do you
get around this?
The design pattern that solves this kind of problem is called
a “visitor” (the final one in the Design Patterns book), and
it builds on the double dispatching scheme shown in the last
section.
The visitor
pattern allows you to extend the interface of the primary type by creating a
separate class hierarchy of type Visitor to virtualize the operations
performed upon the primary type. The objects of the primary type simply
“accept” the visitor, then call the visitor’s
dynamically-bound member function.
//: C10:BeeAndFlowers.cpp
// Demonstration of "visitor" pattern
#include "../purge.h"
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#include <cstdlib>
#include <ctime>
using namespace std;
class Gladiolus;
class Renuculus;
class Chrysanthemum;
class Visitor {
public:
virtual void visit(Gladiolus* f) = 0;
virtual void visit(Renuculus* f) = 0;
virtual void visit(Chrysanthemum* f) = 0;
virtual ~Visitor() {}
};
class Flower {
public:
virtual void accept(Visitor&) = 0;
virtual ~Flower() {}
};
class Gladiolus : public Flower {
public:
virtual void accept(Visitor& v) {
v.visit(this);
}
};
class Renuculus : public Flower {
public:
virtual void accept(Visitor& v) {
v.visit(this);
}
};
class Chrysanthemum : public Flower {
public:
virtual void accept(Visitor& v) {
v.visit(this);
}
};
// Add the ability to produce a string:
class StringVal : public Visitor {
string s;
public:
operator const string&() { return s; }
virtual void visit(Gladiolus*) {
s = "Gladiolus";
}
virtual void visit(Renuculus*) {
s = "Renuculus";
}
virtual void visit(Chrysanthemum*) {
s = "Chrysanthemum";
}
};
// Add the ability to do "Bee" activities:
class Bee : public Visitor {
public:
virtual void visit(Gladiolus*) {
cout << "Bee and Gladiolus\n";
}
virtual void visit(Renuculus*) {
cout << "Bee and Renuculus\n";
}
virtual void visit(Chrysanthemum*) {
cout << "Bee and Chrysanthemum\n";
}
};
struct FlowerGen {
FlowerGen() { srand(time(0)); }
Flower* operator()() {
switch(rand() % 3) {
default:
case 0: return new Gladiolus;
case 1: return new Renuculus;
case 2: return new Chrysanthemum;
}
}
};
int main() {
vector<Flower*> v(10);
generate(v.begin(), v.end(), FlowerGen());
vector<Flower*>::iterator it;
// It's almost as if I added a virtual function
// to produce a Flower string representation:
StringVal sval;
for(it = v.begin(); it != v.end(); it++) {
(*it)->accept(sval);
cout << string(sval) << endl;
}
// Perform "Bee" operation on all Flowers:
Bee bee;
for(it = v.begin(); it != v.end(); it++)
(*it)->accept(bee);
purge(v);}
///:~
The nature of this problem (modeling a trash recycling system)
is that the trash is thrown unclassified into a single bin, so the specific type
information is lost. But later, the specific type information must be recovered
to properly sort the trash. In the initial solution, RTTI (described in Chapter
XX) is used.
This is not a trivial design because it has an added
constraint. That’s what makes it interesting – it’s more like
the messy problems you’re likely to encounter in your work. The extra
constraint is that the trash arrives at the trash recycling plant all mixed
together. The program must model the sorting of that trash. This is where RTTI
comes in: you have a bunch of anonymous pieces of trash, and the program figures
out exactly what type they are.
One of the objectives of this program is to sum up the weight
and value of the different types of trash. The trash will be kept in
(potentially different types of) containers, so it makes sense to templatize the
“summation” function on the container holding it (assuming that
container exhibits basic STL-like behavior), so the function will be maximally
flexible:
//: C10:sumValue.h
// Sums the value of Trash in any type of STL
// container of any specific type of Trash:
#ifndef SUMVALUE_H
#define SUMVALUE_H
#include <typeinfo>
#include <vector>
template<typename Cont>
void sumValue(const Cont& bin) {
double val = 0.0f;
typename Cont::iterator tally = bin.begin();
while(tally != bin.end()) {
val +=(*tally)->weight() * (*tally)->value();
out << "weight of "
<< typeid(*(*tally)).name()
<< " = " << (*tally)->weight()
<< endl;
tally++;
}
out << "Total value = " << val << endl;
}#endif // SUMVALUE_H
///:~
When you look at a piece of code like this, it can be
initially disturbing because you might wonder “how can the compiler know
that the member functions I’m calling here are valid?” But of
course, all the template says is “generate this code on demand,” and
so only when you call the function will type checking come into play. This
enforces that *tally produces an object that has member functions
weight( ) and value( ), and that out is a global
ostream.
The sumValue( ) function is templatized on the
type of container that’s holding the Trash pointers. Notice
there’s nothing in the template signature that says “this container
must behave like an STL container and must hold Trash*”; that is
all implied in the code that’s generated which uses the
container.
The first version of the example takes the straightforward
approach: creating a vector<Trash*>, filling it with Trash
objects, then using RTTI to sort them out:
//: C10:Recycle1.cpp
// Recycling with RTTI
#include "sumValue.h"
#include "../purge.h"
#include <fstream>
#include <vector>
#include <typeinfo>
#include <cstdlib>
#include <ctime>
using namespace std;
ofstream out("Recycle1.out");
class Trash {
double _weight;
static int _count; // # created
static int _dcount; // # destroyed
// disallow automatic creation of
// assignment & copy-constructor:
void operator=(const Trash&);
Trash(const Trash&);
public:
Trash(double wt) : _weight(wt) {
_count++;
}
virtual double value() const = 0;
double weight() const { return _weight; }
static int count() { return _count; }
static int dcount() { return _dcount;}
virtual ~Trash() { _dcount++; }
};
int Trash::_count = 0;
int Trash::_dcount = 0;
class Aluminum : public Trash {
static double val;
public:
Aluminum(double wt) : Trash(wt) {}
double value() const { return val; }
static void value(double newval) {
val = newval;
}
~Aluminum() { out << "~Aluminum\n"; }
};
double Aluminum::val = 1.67F;
class Paper : public Trash {
static double val;
public:
Paper(double wt) : Trash(wt) {}
double value() const { return val; }
static void value(double newval) {
val = newval;
}
~Paper() { out << "~Paper\n"; }
};
double Paper::val = 0.10F;
class Glass : public Trash {
static double val;
public:
Glass(double wt) : Trash(wt) {}
double value() const { return val; }
static void value(double newval) {
val = newval;
}
~Glass() { out << "~Glass\n"; }
};
double Glass::val = 0.23F;
class TrashGen {
public:
TrashGen() { srand(time(0)); }
static double frand(int mod) {
return static_cast<double>(rand() % mod);
}
Trash* operator()() {
for(int i = 0; i < 30; i++)
switch(rand() % 3) {
case 0 :
return new Aluminum(frand(100));
case 1 :
return new Paper(frand(100));
case 2 :
return new Glass(frand(100));
}
return new Aluminum(0);
// Or throw exeception...
}
};
int main() {
vector<Trash*> bin;
// Fill up the Trash bin:
generate_n(back_inserter(bin), 30, TrashGen());
vector<Aluminum*> alBin;
vector<Paper*> paperBin;
vector<Glass*> glassBin;
vector<Trash*>::iterator sorter = bin.begin();
// Sort the Trash:
while(sorter != bin.end()) {
Aluminum* ap =
dynamic_cast<Aluminum*>(*sorter);
Paper* pp = dynamic_cast<Paper*>(*sorter);
Glass* gp = dynamic_cast<Glass*>(*sorter);
if(ap) alBin.push_back(ap);
if(pp) paperBin.push_back(pp);
if(gp) glassBin.push_back(gp);
sorter++;
}
sumValue(alBin);
sumValue(paperBin);
sumValue(glassBin);
sumValue(bin);
out << "total created = "
<< Trash::count() << endl;
purge(bin);
out << "total destroyed = "
<< Trash::dcount() << endl;}
///:~
This uses the classic structure of virtual functions in the
base class that are redefined in the derived class. In addition, there are two
static data members in the base class: _count to indicate
the number of Trash objects that are created, and _dcount to keep
track of the number that are destroyed. This verifies that proper memory
management occurs. To support this, the operator= and copy-constructor
are disallowed by declaring them private (no definitions are necessary;
this simply prevents the compiler from synthesizing them). Those operations
would cause problems with the count, and if they were allowed you’d have
to define them properly.
The Trash objects are created, for the sake of this
example, by the generator TrashGen, which uses the random number
generator to choose the type of Trash, and also to provide it with a
“weight” argument. The return value of the generator’s
operator( ) is upcast to Trash*, so all the specific type
information is lost. In main( ), a
vector<Trash*> called bin is created and then filled using
the STL algorithm generate_n( ). To perform the sorting, three
vectors are created, each of which holds a different type of
Trash*. An iterator moves through bin and RTTI is used to
determine which specific type of Trash the iterator is currently
selecting, placing each into the appropriate typed bin. Finally,
sumValue( ) is applied to each of the containers, and the Trash
objects are cleaned up using purge( ) (defined in Chapter XX).
The creation and destruction counts ensure that things are properly cleaned
up.
Of course, it seems silly to upcast the types of Trash
into a container holding base type pointers, and then to turn around and
downcast. Why not just put the trash into the appropriate receptacle in the
first place? (indeed, this is the whole enigma of recycling). In this program it
might be easy to repair, but sometimes a system’s structure and
flexibility can benefit greatly from downcasting.
The program satisfies the design requirements: it works. This
may be fine as long as it’s a one-shot solution. However, a good program
will evolve over time, so you must ask: what if the situation changes? For
example, cardboard is now a valuable recyclable commodity, so how will that be
integrated into the system (especially if the program is large and complicated).
Since the above type-check coding in the switch statement and in the RTTI
statements could be scattered throughout the program, you’d have to go
find all that code every time a new type was added, and if you miss one the
compiler won’t help you.
The key to the misuse of RTTI here is that every type is
tested. If you’re only looking for a subset of types because that
subset needs special treatment, that’s probably fine. But if you’re
hunting for every type inside a switch statement, then you’re
probably missing an important point, and definitely making your code less
maintainable. In the next section we’ll look at how this program evolved
over several stages to become much more flexible. This should prove a valuable
example in program
design.
The solutions in Design Patterns are organized around
the question “What will change as this program evolves?” This is
usually the most important question that you can ask about any design. If you
can build your system around the answer, the results will be two-pronged: not
only will your system allow easy (and inexpensive) maintenance, but you might
also produce components that are reusable, so that other systems can be built
more cheaply. This is the promise of object-oriented programming, but it
doesn’t happen automatically; it requires thought and insight on your
part. In this section we’ll see how this process can happen during the
refinement of a system.
The answer to the question “What will change?” for
the recycling system is a common one: more types will be added to the system.
The goal of the design, then, is to make this addition of types as painless as
possible. In the recycling program, we’d like to encapsulate all places
where specific type information is mentioned, so (if for no other reason) any
changes can be localized inside those encapsulations. It turns out that this
process also cleans up the rest of the code
considerably.
This brings up a general object-oriented design principle that
I first heard spoken by Grady Booch: “If the design
is too complicated, make more objects.” This is simultaneously
counterintuitive and ludicrously simple, and yet it’s the most useful
guideline I’ve found. (You might observe that “make more
objects” is often equivalent to “add another level of
indirection.”) In general, if you find a place with messy code, consider
what sort of class would clean things up. Often the side effect of cleaning up
the code will be a system that has better structure and is more
flexible.
Consider first the place where Trash objects are
created. In the above example, we’re conveniently using a generator to
create the objects. The generator nicely encapsulates the creation of the
objects, but the neatness is an illusion because in general we’ll want to
create the objects based on something more than a random number generator. Some
information will be available which will determine what kind of Trash
object this should be. Because you generally need to make your objects by
examining some kind of information, if you’re not paying close attention
you may end up with switch statements (as in TrashGen) or cascaded
if statements scattered throughout your code. This is definitely messy,
and also a place where you must change code whenever a new type is added. If new
types are commonly added, a better solution is a single member function that
takes all of the necessary information and produces an object of the correct
type, already upcast to a Trash pointer. In Design Patterns this
is broadly referred to as a
creational pattern (of
which there are several). The specific pattern that will be applied here is a
variant of the Factory
Method (“method” being a more OOPish way to refer to a member
function). Here, the factory method will be a static member of
Trash, but more commonly it is a member function that is overridden in
the derived class.
The idea of the factory method is that you pass it the
essential information it needs to know to create your object, then stand back
and wait for the pointer (already upcast to the base type) to pop out as the
return value. From then on, you treat the object polymorphically. Thus, you
never even need to know the exact type of object that’s created. In fact,
the factory method hides it from you to prevent accidental misuse. If you want
to use the object without polymorphism, you must explicitly use RTTI and
casting.
But there’s a little problem, especially when you use
the more complicated approach (not shown here) of making the factory method in
the base class and overriding it in the derived classes. What if the information
required in the derived class requires more or different arguments?
“Creating more objects” solves this problem. To implement the
factory method, the Trash class gets a new member function called
factory( ). To hide the creational data, there’s a new class
called Info that contains all of the necessary information for the
factory( ) method to create the appropriate Trash object.
Here’s a simple implementation of Info:
class Info {
int type;
// Must change this to add another type:
static const int maxnum = 3;
double data;
public:
Info(int typeNum, double dat)
: type(typeNum % maxnum), data(dat) {}
};
An Info object’s only job is to hold information
for the factory( ) method. Now, if there’s a situation in
which factory( ) needs more or different information to create a new
type of Trash object, the factory( ) interface doesn’t
need to be changed. The Info class can be changed by adding new data and
new constructors, or in the more typical object-oriented fashion of
subclassing.
Here’s the second version of the program with the
factory method added. The object-counting code has been removed; we’ll
assume proper cleanup will take place in all the rest of the examples.
//: C10:Recycle2.cpp
// Adding a factory method
#include "sumValue.h"
#include "../purge.h"
#include <fstream>
#include <vector>
#include <typeinfo>
#include <cstdlib>
#include <ctime>
using namespace std;
ofstream out("Recycle2.out");
class Trash {
double _weight;
void operator=(const Trash&);
Trash(const Trash&);
public:
Trash(double wt) : _weight(wt) { }
virtual double value() const = 0;
double weight() const { return _weight; }
virtual ~Trash() {}
// Nested class because it's tightly coupled
// to Trash:
class Info {
int type;
// Must change this to add another type:
static const int maxnum = 3;
double data;
friend class Trash;
public:
Info(int typeNum, double dat)
: type(typeNum % maxnum), data(dat) {}
};
static Trash* factory(const Info& info);
};
class Aluminum : public Trash {
static double val;
public:
Aluminum(double wt) : Trash(wt) {}
double value() const { return val; }
static void value(double newval) {
val = newval;
}
~Aluminum() { out << "~Aluminum\n"; }
};
double Aluminum::val = 1.67F;
class Paper : public Trash {
static double val;
public:
Paper(double wt) : Trash(wt) {}
double value() const { return val; }
static void value(double newval) {
val = newval;
}
~Paper() { out << "~Paper\n"; }
};
double Paper::val = 0.10F;
class Glass : public Trash {
static double val;
public:
Glass(double wt) : Trash(wt) {}
double value() const { return val; }
static void value(double newval) {
val = newval;
}
~Glass() { out << "~Glass\n"; }
};
double Glass::val = 0.23F;
// Definition of the factory method. It must know
// all the types, so is defined after all the
// subtypes are defined:
Trash* Trash::factory(const Info& info) {
switch(info.type) {
default: // In case of overrun
case 0:
return new Aluminum(info.data);
case 1:
return new Paper(info.data);
case 2:
return new Glass(info.data);
}
}
// Generator for Info objects:
class InfoGen {
int typeQuantity;
int maxWeight;
public:
InfoGen(int typeQuant, int maxWt)
: typeQuantity(typeQuant), maxWeight(maxWt) {
srand(time(0));
}
Trash::Info operator()() {
return Trash::Info(rand() % typeQuantity,
static_cast<double>(rand() % maxWeight));
}
};
int main() {
vector<Trash*> bin;
// Fill up the Trash bin:
InfoGen infoGen(3, 100);
for(int i = 0; i < 30; i++)
bin.push_back(Trash::factory(infoGen()));
vector<Aluminum*> alBin;
vector<Paper*> paperBin;
vector<Glass*> glassBin;
vector<Trash*>::iterator sorter = bin.begin();
// Sort the Trash:
while(sorter != bin.end()) {
Aluminum* ap =
dynamic_cast<Aluminum*>(*sorter);
Paper* pp = dynamic_cast<Paper*>(*sorter);
Glass* gp = dynamic_cast<Glass*>(*sorter);
if(ap) alBin.push_back(ap);
if(pp) paperBin.push_back(pp);
if(gp) glassBin.push_back(gp);
sorter++;
}
sumValue(alBin);
sumValue(paperBin);
sumValue(glassBin);
sumValue(bin);
purge(bin); // Cleanup}
///:~
In the factory method Trash::factory( ), the
determination of the exact type of object is simple, but you can imagine a more
complicated system in which factory( ) uses an elaborate algorithm.
The point is that it’s now hidden away in one place, and you know to come
to this place to make changes when you add new types.
The creation of new objects is now more general in
main( ), and depends on “real” data (albeit created by
another generator, driven by random numbers). The generator object is created,
telling it the maximum type number and the largest “data” value to
produce. Each call to the generator creates an Info object which is
passed into Trash::factory( ), which in turn produces some kind of
Trash object and returns the pointer that’s added to the
vector<Trash*> bin.
The constructor for the Info object is very specific
and restrictive in this example. However, you could also imagine a vector
of arguments into the Info constructor (or directly into a
factory( ) call, for that matter). This requires that the arguments
be parsed and checked at runtime, but it does provide the greatest
flexibility.
You can see from this code what
“vector
of change” problem the factory is responsible for solving: if you add new
types to the system (the change), the only code that must be modified is within
the factory, so the factory isolates the effect of that
change.
A problem with the above design is that it still requires a
central location where all the types of the objects must be known: inside the
factory( ) method. If new types are regularly being added to the
system, the factory( ) method must be changed for each new type.
When you discover something like this, it is useful to try to go one step
further and move all of the activities involving that specific type
– including its creation – into the class representing that type.
This way, the only thing you need to do to add a new type to the system is to
inherit a single class.
To move the information concerning type creation into each
specific type of Trash, the
“prototype” pattern
will be used. The general idea is that you have a master container of objects,
one of each type you’re interested in making. The “prototype
objects” in this container are used only for making new objects. In
this case, we’ll name the object-creation member function
clone( ). When you’re ready to make a new object,
presumably you have some sort of information that establishes the type of object
you want to create. The factory( ) method (it’s not required
that you use factory with prototype, but they commingle nicely) moves through
the master container comparing your information with whatever appropriate
information is in the prototype objects in the master container. When a match is
found, factory( ) returns a clone of that object.
In this scheme there is no hard-coded information for
creation. Each object knows how to expose appropriate information to allow
matching, and how to clone itself. Thus, the factory( ) method
doesn’t need to be changed when a new type is added to the system.
The prototypes will be contained in a static
vector<Trash*> called prototypes. This is a private
member of the base class Trash. The friend class
TrashPrototypeInit is responsible for putting the Trash*
prototypes into the prototype list.
You’ll also note that the Info class has changed.
It now uses a string to act as type identification information. As you
shall see, this will allow us to read object information from a file when
creating Trash objects.
//: C10:Trash.h
// Base class for Trash recycling examples
#ifndef TRASH_H
#define TRASH_H
#include <iostream>
#include <exception>
#include <vector>
#include <string>
class TypedBin; // For a later example
class Visitor; // For a later example
class Trash {
double _weight;
void operator=(const Trash&);
Trash(const Trash&);
public:
Trash(double wt) : _weight(wt) {}
virtual double value() const = 0;
double weight() const { return _weight; }
virtual ~Trash() {}
class Info {
std::string _id;
double _data;
public:
Info(std::string ident, double dat)
: _id(ident), _data(dat) {}
double data() const { return _data; }
std::string id() const { return _id; }
friend std::ostream& operator<<(
std::ostream& os, const Info& info) {
return os << info._id << ':' << info._data;
}
};
protected:
// Remainder of class provides support for
// prototyping:
static std::vector<Trash*> prototypes;
friend class TrashPrototypeInit;
Trash() : _weight(0) {}
public:
static Trash* factory(const Info& info);
virtual std::string id() = 0; // type ident
virtual Trash* clone(const Info&) = 0;
// Stubs, inserted for later use:
virtual bool
addToBin(std::vector<TypedBin*>&) {
return false;
}
virtual void accept(Visitor&) {};
};#endif // TRASH_H
///:~
The basic part of the Trash class remains as before.
The rest of the class supports the prototyping pattern. The id( )
member function returns a string that can be compared with the
id( ) of an Info object to determine whether this is the
prototype that should be cloned (of course, the evaluation can be much more
sophisticated than that if you need it). Both id( ) and
clone( ) are pure virtual functions so they must be
overridden in derived classes.
The last two member functions, addToBin( ) and
accept( ), are “stubs” which will be used in later
versions of the trash sorting problem. It’s necessary to have these
virtual functions in the base class, but in the early examples there’s no
need for them, so they are not pure virtuals so as not to intrude.
The factory( ) member function has the same
declaration, but the definition is what handles the prototyping. Here is the
implementation file:
//: C10:Trash.cpp {O}
#include "Trash.h"
using namespace std;
Trash* Trash::factory(const Info& info) {
vector<Trash*>::iterator it;
for(it = prototypes.begin();
it != prototypes.end(); it++) {
// Somehow determine the new type
// to create, and clone one:
if (info.id() == (*it)->id())
return (*it)->clone(info);
}
cerr << "Prototype not found for "
<< info << endl;
// "Default" to first one in the vector:
return (*prototypes.begin())->clone(info);}
///:~
The string inside the Info object contains the
type name of the Trash to be created; this string is compared to
the id( ) values of the objects in prototypes. If
there’s a match, then that’s the object to create.
Of course, the appropriate prototype object might not be in
the prototypes list. In this case, the return in the inner loop is
never executed and you’ll drop out at the end, where a default value is
created. It might be more appropriate to throw an exception here.
As you can see from the code, there’s nothing that knows
about specific types of Trash. The beauty of this design is that this
code doesn’t need to be changed, regardless of the different situations it
will be used in.
To fit into the prototyping scheme, each new subclass of
Trash must follow some rules. First, it must create a protected
default constructor, so that no one but TrashPrototypeInit may use it.
TrashPrototypeInit is a singleton, creating one and only one prototype
object for each subtype. This guarantees that the Trash subtype will
be properly represented in the prototypes container.
After defining the “ordinary” member functions and
data that the Trash object will actually use, the class must also
override the id( ) member (which in this case returns a
string for comparison) and the clone( ) function, which must
know how to pull the appropriate information out of the Info object in
order to create the object correctly.
Here are the different types of Trash, each in their
own file.
//: C10:Aluminum.h
// The Aluminum class with prototyping
#ifndef ALUMINUM_H
#define ALUMINUM_H
#include "Trash.h"
class Aluminum : public Trash {
static double val;
protected:
Aluminum() {}
friend class TrashPrototypeInit;
public:
Aluminum(double wt) : Trash(wt) {}
double value() const { return val; }
static void value(double newVal) {
val = newVal;
}
std::string id() { return "Aluminum"; }
Trash* clone(const Info& info) {
return new Aluminum(info.data());
}
};#endif // ALUMINUM_H
///:~
//: C10:Paper.h
// The Paper class with prototyping
#ifndef PAPER_H
#define PAPER_H
#include "Trash.h"
class Paper : public Trash {
static double val;
protected:
Paper() {}
friend class TrashPrototypeInit;
public:
Paper(double wt) : Trash(wt) {}
double value() const { return val; }
static void value(double newVal) {
val = newVal;
}
std::string id() { return "Paper"; }
Trash* clone(const Info& info) {
return new Paper(info.data());
}
};#endif // PAPER_H
///:~
//: C10:Glass.h
// The Glass class with prototyping
#ifndef GLASS_H
#define GLASS_H
#include "Trash.h"
class Glass : public Trash {
static double val;
protected:
Glass() {}
friend class TrashPrototypeInit;
public:
Glass(double wt) : Trash(wt) {}
double value() const { return val; }
static void value(double newVal) {
val = newVal;
}
std::string id() { return "Glass"; }
Trash* clone(const Info& info) {
return new Glass(info.data());
}
};#endif // GLASS_H
///:~
And here’s a new type of Trash:
//: C10:Cardboard.h
// The Cardboard class with prototyping
#ifndef CARDBOARD_H
#define CARDBOARD_H
#include "Trash.h"
class Cardboard : public Trash {
static double val;
protected:
Cardboard() {}
friend class TrashPrototypeInit;
public:
Cardboard(double wt) : Trash(wt) {}
double value() const { return val; }
static void value(double newVal) {
val = newVal;
}
std::string id() { return "Cardboard"; }
Trash* clone(const Info& info) {
return new Cardboard(info.data());
}
};#endif // CARDBOARD_H
///:~
The static val data members must be defined and
initialized in a separate code file:
//: C10:TrashStatics.cpp {O}
// Contains the static definitions for
// the Trash type's "val" data members
#include "Trash.h"
#include "Aluminum.h"
#include "Paper.h"
#include "Glass.h"
#include "Cardboard.h"
double Aluminum::val = 1.67;
double Paper::val = 0.10;
double Glass::val = 0.23;
double Cardboard::val = 0.14;///:~
There’s one other issue: initialization of the static
data members. TrashPrototypeInit must create the prototype objects and
add them to the static Trash::prototypes vector. So it’s
very important that you control the order of initialization of the
static objects, so the prototypes vector is created before any of
the prototype objects, which depend on the prior existence of prototypes.
The most straightforward way to do this is to put all the definitions in a
single file, in the order in which you want them initialized.
TrashPrototypeInit must be defined separately because
it inserts the actual prototypes into the vector, and throughout the
chapter we’ll be inheriting new types of Trash from the existing
types. By making this one class in a separate file, a different version can be
created and linked in for the new situations, leaving the rest of the code in
the system alone.
//: C10:TrashPrototypeInit.cpp {O}
// Performs initialization of all the prototypes.
// Create a different version of this file to
// make different kinds of Trash.
#include "Trash.h"
#include "Aluminum.h"
#include "Paper.h"
#include "Glass.h"
#include "Cardboard.h"
// Allocate the static member object:
std::vector<Trash*> Trash::prototypes;
class TrashPrototypeInit {
Aluminum a;
Paper p;
Glass g;
Cardboard c;
TrashPrototypeInit() {
Trash::prototypes.push_back(&a);
Trash::prototypes.push_back(&p);
Trash::prototypes.push_back(&g);
Trash::prototypes.push_back(&c);
}
static TrashPrototypeInit singleton;
};
TrashPrototypeInit
TrashPrototypeInit::singleton; ///:~
This is taken a step further by making
TrashPrototypeInit a singleton (the constructor is private), even
though the class definition is not available in a header file so it would seem
safe enough to assume that no one could accidentally make a second
instance.
Unfortunately, this is one more separate piece of code you
must maintain whenever you add a new type to the system. However, it’s not
too bad since the linker should give you an error message if you forget (since
prototypes is defined in this file as well). The really difficult
problems come when you don’t get any warnings or errors if you do
something wrong.
The information about Trash objects will be read from
an outside file. The file has all of the necessary information about each piece
of trash in a single entry in the form Trash:weight. There are multiple
entries on a line, separated by commas:
//:! C10:Trash.dat Glass:54, Paper:22, Paper:11, Glass:17, Aluminum:89, Paper:88, Aluminum:76, Cardboard:96, Aluminum:25, Aluminum:34, Glass:11, Glass:68, Glass:43, Aluminum:27, Cardboard:44, Aluminum:18, Paper:91, Glass:63, Glass:50, Glass:80, Aluminum:81, Cardboard:12, Glass:12, Glass:54, Aluminum:36, Aluminum:93, Glass:93, Paper:80, Glass:36, Glass:12, Glass:60, Paper:66, Aluminum:36, Cardboard:22,
///:~
To parse this, the line is read and the
string member function
find( ) produces the index of the
‘:’. This is first used with the string member
function substr( ) to
extract the name of the trash type, and next to get the weight that is turned
into a double with the atof( ) function (from
<cstdlib>).
The Trash file parser is placed in a separate file
since it will be reused throughout this chapter. To facilitate this reuse, the
function fillBin( ) which does the work takes as its first argument
the name of the file to open and read, and as its second argument a reference to
an object of type Fillable. This uses what I’ve named the
“interface” idiom at the beginning of the chapter, and the only
attribute for this particular interface is that “it can be filled,”
via a member function addTrash( ). Here’s the header file for
Fillable:
//: C10:Fillable.h
// Any object that can be filled with Trash
#ifndef FILLABLE_H
#define FILLABLE_H
class Fillable {
public:
virtual void addTrash(Trash* t) = 0;
};#endif // FILLABLE_H
///:~
Notice that it follows the interface idiom of having no
non-static data members, and all pure virtual member functions.
This way, any class which implements this interface (typically
using multiple inheritance) can be filled using fillBin( ).
Here’s the header file:
//: C10:fillBin.h
// Open a file and parse its contents into
// Trash objects, placing each into a vector
#ifndef FILLBIN_H
#define FILLBIN_H
#include "Fillablevector.h"
#include <vector>
#include <string>
void
fillBin(std::string filename, Fillable& bin);
// Special case to handle vector:
inline void fillBin(std::string filename,
std::vector<Trash*>& bin) {
Fillablevector fv(bin);
fillBin(filename, fv);
}#endif // FILLBIN_H
///:~
The overloaded version will be discussed shortly. First, here
is the implementation:
//: C10:fillBin.cpp {O}
// Implementation of fillBin()
#include "fillBin.h"
#include "Fillable.h""AAA">
#include "../C01/trim.h"
#include "../require.h"
#include <fstream>
#include <string>
#include <cstdlib>
using namespace std;
void fillBin(string filename, Fillable& bin) {
ifstream in(filename.c_str());
assure(in, filename.c_str());
string s;
while(getline(in, s)) {
int comma = s.find(',');
// Parse each line into entries:
while(comma != string::npos) {
string e = trim(s.substr(0,comma));
// Parse each entry:
int colon = e.find(':');
string type = e.substr(0, colon);
double weight =
atof(e.substr(colon + 1).c_str());
bin.addTrash(
Trash::factory(
Trash::Info(type, weight)));
// Move to next part of line:
s = s.substr(comma + 1);
comma = s.find(',');
}
}}
///:~
After the file is opened, each line is read and parsed into
entries by looking for the separating comma, then each entry is parsed into its
type and weight by looking for the separating colon. Note the convenience of
using the trim( ) function from chapter 17 to remove the white space
from both ends of a string. Once the type and weight are discovered, an
Info object is created from that data and passed to the
factory( ). The result of this call is a Trash* which is
passed to the addTrash( ) function of the bin (which is the
only function, remember, that a Fillable guarantees).
Anything that supports the Fillable interface can be
used with fillBin( ). Of course, vector doesn’t
implement Fillable, so it won’t work. Since vector is used
in most of the examples, it makes sense to add the second overloaded
fillBin( ) function that takes a vector, as seen previously
in fillBin.h. But how to make a vector<Trash*> adapt to the
Fillable interface, which says it must have an addTrash( )
member function? The key is in the word “adapt”; we use the
adapter pattern to create a class that has a vector and is also
Fillable.
By saying “is also Fillable,” the hint is
strong (is-a) to inherit from Fillable. But what about the
vector<Trash*>? Should this new class inherit from that? We
don’t actually want to be making a new kind of vector, which would
force everyone to only use our vector in this situation. Instead, we want
someone to be able to have their own vector and say “please fill
this.” So the new class should just keep a reference to that
vector:
//: C10:Fillablevector.h
// Adapter that makes a vector<Trash*> Fillable
#ifndef FILLABLEVECTOR_H
#define FILLABLEVECTOR_H
#include "Trash.h"
#include "Fillable.h"
#include <vector>
class Fillablevector : public Fillable {
std::vector<Trash*>& v;
public:
Fillablevector(std::vector<Trash*>& vv)
: v(vv) {}
void addTrash(Trash* t) { v.push_back(t); }
};#endif //
FILLABLEVECTOR_H ///:~
You can see that the only job of this class is to connect
Fillable’s addTrash( ) member function to
vector’s push_back( ) (that’s the
“adapter” motivation). With this class in hand, the overloaded
fillBin( ) member function can be used with a vector in
fillBin.h:
inline void fillBin(std::string filename,
std::vector<Trash*>& bin) {
Fillablevector fv(bin);
fillBin(filename, fv);}
Notice that the adapter object fv only exists for the
duration of the function call, and it wraps bin in an interface that
works with the other fillBin( ) function.
This approach works for any container class that’s used
frequently. Alternatively, the container can multiply inherit from
Fillable. (You’ll see this later, in
DynaTrash.cpp.)
//: C10:Recycle3.cpp
//{L} TrashPrototypeInit
//{L} fillBin Trash TrashStatics
// Recycling with RTTI and Prototypes
#include "Trash.h"
#include "Aluminum.h"
#include "Paper.h"
#include "Glass.h"
#include "fillBin.h"
#include "sumValue.h"
#include "../purge.h"
#include <fstream>
#include <vector>
using namespace std;
ofstream out("Recycle3.out");
int main() {
vector<Trash*> bin;
// Fill up the Trash bin:
fillBin("Trash.dat", bin);
vector<Aluminum*> alBin;
vector<Paper*> paperBin;
vector<Glass*> glassBin;
vector<Trash*>::iterator it = bin.begin();
while(it != bin.end()) {
// Sort the Trash:
Aluminum* ap =
dynamic_cast<Aluminum*>(*it);
Paper* pp = dynamic_cast<Paper*>(*it);
Glass* gp = dynamic_cast<Glass*>(*it);
if(ap) alBin.push_back(ap);
if(pp) paperBin.push_back(pp);
if(gp) glassBin.push_back(gp);
it++;
}
sumValue(alBin);
sumValue(paperBin);
sumValue(glassBin);
sumValue(bin);
purge(bin);}
///:~
The process of opening the data file containing Trash
descriptions and the parsing of that file have been wrapped into
fillBin( ), so now it’s no longer a part of our design focus.
You will see that throughout the rest of the chapter, no matter what new classes
are added, fillBin( ) will continue to work without change, which
indicates a good design.
In terms of object creation, this design does indeed severely
localize the changes you need to make to add a new type to the system. However,
there’s a significant problem in the use of RTTI that shows up clearly
here. The program seems to run fine, and yet it never detects any cardboard,
even though there is cardboard in the list of trash data! This happens
because of the use of RTTI, which looks for only the types that you tell
it to look for. The clue that RTTI is being misused is
that every type in the system is being tested, rather than a single type
or subset of types. But if you forget to test for your new type, the compiler
has nothing to say about it.
As you will see later, there are ways to use polymorphism
instead when you’re testing for every type. But if you use RTTI a lot in
this fashion, and you add a new type to your system, you can easily forget to
make the necessary changes in your program and produce a difficult-to-find bug.
So it’s worth trying to eliminate RTTI in this case, not just for
aesthetic reasons – it produces more maintainable
code.
With creation out of the way, it’s time to tackle the
remainder of the design: where the classes are used. Since it’s the act of
sorting into bins that’s particularly ugly and exposed, why not take that
process and hide it inside a class? This is simple “complexity
hiding,” the principle of “If you must do something ugly, at least
localize the ugliness.” In an OOP language, the best place to hide
complexity is inside a class. Here’s a first cut:
A TrashSorter object holds a vector that somehow
connects to vectors holding specific types of Trash. The most
convenient solution would be a vector<vector<Trash*>>, but
it’s too early to tell if that would work out best.
In addition, we’d like to have a sort( )
function as part of the TrashSorter class. But, keeping in mind that
the goal is easy addition of new types of Trash, how would the
statically-coded sort( ) function deal with the fact that a new type
has been added? To solve this, the type information must be removed from
sort( ) so all it needs to do is call a generic function which takes
care of the details of type. This, of course, is another way to describe a
virtual function. So sort( ) will simply move through the
vector of Trash bins and call a virtual function for each.
I’ll call the function grab(Trash*), so the structure now looks
like this:
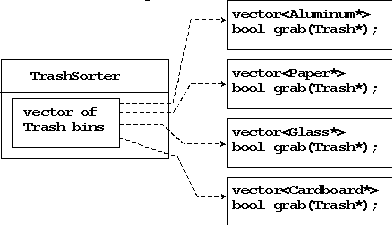
However, TrashSorter needs to call grab( )
polymorphically, through a common base class for all the vectors. This
base class is very simple, since it only needs to establish the interface for
the grab( ) function.
Now there’s a choice. Following the above diagram, you
could put a vector of trash pointers as a member object of each
subclassed Tbin. However, you will want to treat each Tbin as a
vector, and perform all the vector operations on it. You could
create a new interface and forward all those operations, but that produces work
and potential bugs. The type we’re creating is really a Tbin
and a vector, which suggests multiple inheritance. However, it
turns out that’s not quite necessary, for the following reason.
Each time a new type is added to the system the programmer
will have to go in and derive a new class for the vector that holds the
new type of Trash, along with its grab( ) function. The code
the programmer writes will actually be identical code except for the type
it’s working with. That last phrase is the key to introduce a
template, which will do all the work of adding a new type. Now the diagram looks
more complicated, although the process of adding a new type to the system will
be simple. Here, TrashBin can inherit from TBin, which inherits
from vector<Trash*> like this (the multiple-lined arrows indicated
template instantiation):
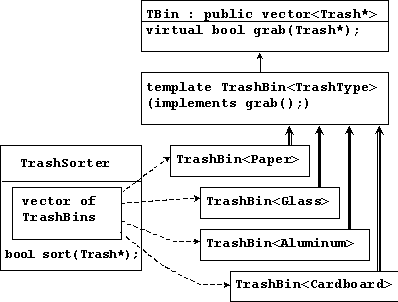
The reason TrashBin must be a template is so it can
automatically generate the grab( ) function. A further
templatization will allow the vectors to hold specific types.
That said, we can look at the whole program to see how all
this is implemented.
//: C10:Recycle4.cpp
//{L} TrashPrototypeInit
//{L} fillBin Trash TrashStatics
// Adding TrashBins and TrashSorters
#include "Trash.h"
#include "Aluminum.h"
#include "Paper.h"
#include "Glass.h"
#include "Cardboard.h"
#include "fillBin.h"
#include "sumValue.h"
#include "../purge.h"
#include <fstream>
#include <vector>
using namespace std;
ofstream out("Recycle4.out");
class TBin : public vector<Trash*> {
public:
virtual bool grab(Trash*) = 0;
};
template<class TrashType>
class TrashBin : public TBin {
public:
bool grab(Trash* t) {
TrashType* tp = dynamic_cast<TrashType*>(t);
if(!tp) return false; // Not grabbed
push_back(tp);
return true; // Object grabbed
}
};
class TrashSorter : public vector<TBin*> {
public:
bool sort(Trash* t) {
for(iterator it = begin(); it != end(); it++)
if((*it)->grab(t))
return true;
return false;
}
void sortBin(vector<Trash*>& bin) {
vector<Trash*>::iterator it;
for(it = bin.begin(); it != bin.end(); it++)
if(!sort(*it))
cerr << "bin not found" << endl;
}
~TrashSorter() { purge(*this); }
};
int main() {
vector<Trash*> bin;
// Fill up the Trash bin:
fillBin("Trash.dat", bin);
TrashSorter tbins;
tbins.push_back(new TrashBin<Aluminum>);
tbins.push_back(new TrashBin<Paper>);
tbins.push_back(new TrashBin<Glass>);
tbins.push_back(new TrashBin<Cardboard>);
tbins.sortBin(bin);
for(TrashSorter::iterator it = tbins.begin();
it != tbins.end(); it++)
sumValue(**it);
sumValue(bin);
purge(bin);}
///:~
TrashSorter needs to call each grab( )
member function and get a different result depending on what type of
Trash the current vector is holding. That is, each vector
must be aware of the type it holds. This “awareness” is accomplished
with a virtual function, the grab( ) function, which thus
eliminates at least the outward appearance of the use of RTTI. The
implementation of grab( ) does use RTTI, but it’s
templatized so as long as you put a new TrashBin in the
TrashSorter when you add a type, everything else is taken care
of.
Memory is managed by denoting bin as the “master
container,” the one responsible for cleanup. With this rule in place,
calling purge( ) for bin cleans up all the Trash
objects. In addition, TrashSorter assumes that it “owns” the
pointers it holds, and cleans up all the TrashBin objects during
destruction.
A basic OOP design principle is “Use data members for
variation in state, use polymorphism for variation in
behavior.” Your first thought might be that the grab( ) member
function certainly behaves differently for a vector that holds
Paper than for one that holds Glass. But what it does is strictly
dependent on the type, and nothing else.
The above design is certainly satisfactory. Adding new types
to the system consists of adding or modifying distinct classes without causing
code changes to be propagated throughout the system. In addition, RTTI is not as
“misused” as it was in Recycle1.cpp. However, it’s
possible to go one step further and eliminate RTTI altogether from the operation
of sorting the trash into bins.
To accomplish this, you must first take the perspective that
all type-dependent activities – such as detecting the type of a piece of
trash and putting it into the appropriate bin – should be controlled
through polymorphism and dynamic binding.
The previous examples first sorted by type, then acted on
sequences of elements that were all of a particular type. But whenever you find
yourself picking out particular types, stop and think. The whole idea of
polymorphism (dynamically-bound member function calls) is to handle
type-specific information for you. So why are you hunting for types?
The multiple-dispatch pattern demonstrated at the beginning of
this chapter uses virtual functions to determine all type information,
thus eliminating
RTTI.
In the Trash hierarchy we will now make use of the
“stub” virtual function addToBin( ) that was added to
the base class Trash but unused up until now. This takes an argument of a
container of TypedBin. A Trash object uses addToBin( )
with this container to step through and try to add itself to the appropriate
bin, and this is where you’ll see the double dispatch.
The new hierarchy is TypedBin, and it contains its own
member function called add( ) that is also used polymorphically. But
here’s an additional twist: add( ) is overloaded to
take arguments of the different types of Trash. So an essential part of
the double dispatching scheme also involves overloading (or at least having a
group of virtual functions to call; overloading happens to be particularly
convenient here).
//: C10:TypedBin.h
#ifndef TYPEDBIN_H
#define TYPEDBIN_H
#include "Trash.h"
#include "Aluminum.h"
#include "Paper.h"
#include "Glass.h"
#include "Cardboard.h"
#include <vector>
// Template to generate double-dispatching
// trash types by inheriting from originals:
template<class TrashType>
class DD : public TrashType {
protected:
DD() : TrashType(0) {}
friend class TrashPrototypeInit;
public:
DD(double wt) : TrashType(wt) {}
bool addToBin(std::vector<TypedBin*>& tb) {
for(int i = 0; i < tb.size(); i++)
if(tb[i]->add(this))
return true;
return false;
}
// Override clone() to create this new type:
Trash* clone(const Trash::Info& info) {
return new DD(info.data());
}
};
// vector<Trash*> that knows how to
// grab the right type
class TypedBin : public std::vector<Trash*> {
protected:
bool addIt(Trash* t) {
push_back(t);
return true;
}
public:
virtual bool add(DD<Aluminum>*) {
return false;
}
virtual bool add(DD<Paper>*) {
return false;
}
virtual bool add(DD<Glass>*) {
return false;
}
virtual bool add(DD<Cardboard>*) {
return false;
}
};
// Template to generate specific TypedBins:
template<class TrashType>
class BinOf : public TypedBin {
public:
// Only overrides add() for this specific type:
bool add(TrashType* t) { return addIt(t); }
};#endif // TYPEDBIN_H
///:~
In each particular subtype of Aluminum, Paper,
Glass, and Cardboard, the addToBin( ) member function
is implemented, but it looks like the code is exactly the same in each
case. The code in each addToBin( ) calls add( ) for each
TypedBin object in the array. But notice the argument: this. The
type of this is different for each subclass of Trash, so the code
is different. So this is the first part of the double dispatch, because once
you’re inside this member function you know you’re Aluminum,
or Paper, etc. During the call to add( ), this information is
passed via the type of this. The compiler resolves the call to the proper
overloaded version of add( ). But since tb[i] produces
a pointer to the base type TypedBin, this call will end up calling
a different member function depending on the type of TypedBin
that’s currently selected. That is the second dispatch.
You can see that the overloaded add( ) methods all
return false. If the member function is not overloaded in a derived
class, it will continue to return false, and the caller
(addToBin( ), in this case) will assume that the current
Trash object has not been added successfully to a container, and continue
searching for the right container.
In each of the subclasses of TypedBin, only one
overloaded member function is overridden, according to the type of bin
that’s being created. For example, CardboardBin overrides
add(DD<Cardboard>). The overridden member function adds the
Trash pointer to its container and returns true, while all the
rest of the add( ) methods in CardboardBin continue to return
false, since they haven’t been overridden. With
C++ templates, you
don’t have to explicitly write the subclasses or place the
addToBin( ) member function in Trash.
To set up for prototyping the new types of trash, there must
be a different initializer file:
//: C10:DDTrashPrototypeInit.cpp {O}
#include "TypedBin.h"
#include "Aluminum.h"
#include "Paper.h"
#include "Glass.h"
#include "Cardboard.h"
std::vector<Trash*> Trash::prototypes;
class TrashPrototypeInit {
DD<Aluminum> a;
DD<Paper> p;
DD<Glass> g;
DD<Cardboard> c;
TrashPrototypeInit() {
Trash::prototypes.push_back(&a);
Trash::prototypes.push_back(&p);
Trash::prototypes.push_back(&g);
Trash::prototypes.push_back(&c);
}
static TrashPrototypeInit singleton;
};
TrashPrototypeInit
TrashPrototypeInit::singleton; ///:~
Here’s the rest of the program:
//: C10:DoubleDispatch.cpp
//{L} DDTrashPrototypeInit
//{L} fillBin Trash TrashStatics
// Using multiple dispatching to handle more than
// one unknown type during a member function call
#include "TypedBin.h"
#include "fillBin.h"
#include "sumValue.h"
#include "../purge.h"
#include <iostream>
#include <fstream>
using namespace std;
ofstream out("DoubleDispatch.out");
class TrashBinSet : public vector<TypedBin*> {
public:
TrashBinSet() {
push_back(new BinOf<DD<Aluminum> >);
push_back(new BinOf<DD<Paper> >);
push_back(new BinOf<DD<Glass> >);
push_back(new BinOf<DD<Cardboard> >);
};
void sortIntoBins(vector<Trash*>& bin) {
vector<Trash*>::iterator it;
for(it = bin.begin(); it != bin.end(); it++)
// Perform the double dispatch:
if(!(*it)->addToBin(*this))
cerr << "Couldn't add " << *it << endl;
}
~TrashBinSet() { purge(*this); }
};
int main() {
vector<Trash*> bin;
TrashBinSet bins;
// fillBin() still works, without changes, but
// different objects are cloned:
fillBin("Trash.dat", bin);
// Sort from the master bin into the
// individually-typed bins:
bins.sortIntoBins(bin);
TrashBinSet::iterator it;
for(it = bins.begin(); it != bins.end(); it++)
sumValue(**it);
// ... and for the master bin
sumValue(bin);
purge(bin);}
///:~
TrashBinSet encapsulates all of the different types of
TypedBins, along with the sortIntoBins( ) member function,
which is where all the double dispatching takes place. You can see that once the
structure is set up, sorting into the various TypedBins is remarkably
easy. In addition, the efficiency of two virtual calls and the double dispatch
is probably better than any other way you could sort.
Notice the ease of use of this system in main( ),
as well as the complete independence of any specific type information within
main( ). All other methods that talk only to the Trash
base-class interface will be equally invulnerable to changes in Trash
types.
The changes necessary to add a new type are relatively
isolated: you inherit the new type of Trash with its
addToBin( ) member function, then make a small modification to
TypedBin, and finally you add a new type into the vector in
TrashBinSet and modify
DDTrashPrototypeInit.cpp.
Now consider applying a design pattern with an entirely
different goal to the trash-sorting problem. As demonstrated earlier in this
chapter, the visitor pattern’s goal is to allow the addition of new
polymorphic operations to a frozen inheritance hierarchy.
For this pattern, we are no longer concerned with optimizing
the addition of new types of Trash to the system. Indeed, this pattern
makes adding a new type of Trash more complicated. It looks like
this: 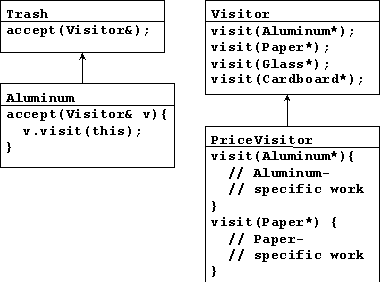
Now, if t is a Trash pointer to an
Aluminum object, the code:
PriceVisitor pv;
t->accept(pv);
causes two polymorphic member function calls: the first one to
select Aluminum’s version of accept( ), and the second
one within accept( ) when the specific version of
visit( ) is called dynamically using the base-class Visitor
pointer v.
This configuration means that new functionality can be added
to the system in the form of new subclasses of Visitor. The Trash
hierarchy doesn’t need to be touched. This is the prime benefit of the
visitor pattern: you can add new polymorphic functionality to a class hierarchy
without touching that hierarchy (once the accept( ) methods have
been installed). Note that the benefit is helpful here but not exactly what we
started out to accomplish, so at first blush you might decide that this
isn’t the desired solution.
But look at one thing that’s been accomplished: the
visitor solution avoids sorting from the master Trash sequence into
individual typed sequences. Thus, you can leave everything in the single master
sequence and simply pass through that sequence using the appropriate visitor to
accomplish the goal. Although this behavior seems to be a side effect of
visitor, it does give us what we want (avoiding RTTI).
The double
dispatching in the visitor pattern takes care of determining both the type of
Trash and the type of Visitor. In the following example,
there are two implementations of Visitor: PriceVisitor to both
determine and sum the price, and WeightVisitor to keep track of the
weights.
You can see all of this implemented in the new, improved
version of the recycling program. As with DoubleDispatch.cpp, the
Trash class has had an extra member function stub
(accept( )) inserted in it to allow for this
example.
Since there’s nothing concrete in the Visitor
base class, it can be created as an interface:
//: C10:Visitor.h
// The base interface for visitors
// and template for visitable Trash types
#ifndef VISITOR_H
#define VISITOR_H
#include "Trash.h"
#include "Aluminum.h"
#include "Paper.h"
#include "Glass.h"
#include "Cardboard.h"
class Visitor {
public:
virtual void visit(Aluminum* a) = 0;
virtual void visit(Paper* p) = 0;
virtual void visit(Glass* g) = 0;
virtual void visit(Cardboard* c) = 0;
};
// Template to generate visitable
// trash types by inheriting from originals:
template<class TrashType>
class Visitable : public TrashType {
protected:
Visitable () : TrashType(0) {}
friend class TrashPrototypeInit;
public:
Visitable(double wt) : TrashType(wt) {}
// Remember "this" is pointer to current type:
void accept(Visitor& v) { v.visit(this); }
// Override clone() to create this new type:
Trash* clone(const Trash::Info& info) {
return new Visitable(info.data());
}
};#endif // VISITOR_H
///:~
As before, a different version of the initialization file is
necessary:
//: C10:VisitorTrashPrototypeInit.cpp {O}
#include "Visitor.h"
std::vector<Trash*> Trash::prototypes;
class TrashPrototypeInit {
Visitable<Aluminum> a;
Visitable<Paper> p;
Visitable<Glass> g;
Visitable<Cardboard> c;
TrashPrototypeInit() {
Trash::prototypes.push_back(&a);
Trash::prototypes.push_back(&p);
Trash::prototypes.push_back(&g);
Trash::prototypes.push_back(&c);
}
static TrashPrototypeInit singleton;
};
TrashPrototypeInit
TrashPrototypeInit::singleton; ///:~
The rest of the program creates specific Visitor types
and sends them through a single list of Trash objects:
//: C10:TrashVisitor.cpp
//{L} VisitorTrashPrototypeInit
//{L} fillBin Trash TrashStatics
// The "visitor" pattern
#include "Visitor.h"
#include "fillBin.h"
#include "../purge.h"
#include <iostream>
#include <fstream>
using namespace std;
ofstream out("TrashVisitor.out");
// Specific group of algorithms packaged
// in each implementation of Visitor:
class PriceVisitor : public Visitor {
double alSum; // Aluminum
double pSum; // Paper
double gSum; // Glass
double cSum; // Cardboard
public:
void visit(Aluminum* al) {
double v = al->weight() * al->value();
out << "value of Aluminum= " << v << endl;
alSum += v;
}
void visit(Paper* p) {
double v = p->weight() * p->value();
out <<
"value of Paper= " << v << endl;
pSum += v;
}
void visit(Glass* g) {
double v = g->weight() * g->value();
out <<
"value of Glass= " << v << endl;
gSum += v;
}
void visit(Cardboard* c) {
double v = c->weight() * c->value();
out <<
"value of Cardboard = " << v << endl;
cSum += v;
}
void total(ostream& os) {
os <<
"Total Aluminum: $" << alSum << "\n" <<
"Total Paper: $" << pSum << "\n" <<
"Total Glass: $" << gSum << "\n" <<
"Total Cardboard: $" << cSum << endl;
}
};
class WeightVisitor : public Visitor {
double alSum; // Aluminum
double pSum; // Paper
double gSum; // Glass
double cSum; // Cardboard
public:
void visit(Aluminum* al) {
alSum += al->weight();
out << "weight of Aluminum = "
<< al->weight() << endl;
}
void visit(Paper* p) {
pSum += p->weight();
out << "weight of Paper = "
<< p->weight() << endl;
}
void visit(Glass* g) {
gSum += g->weight();
out << "weight of Glass = "
<< g->weight() << endl;
}
void visit(Cardboard* c) {
cSum += c->weight();
out << "weight of Cardboard = "
<< c->weight() << endl;
}
void total(ostream& os) {
os << "Total weight Aluminum:"
<< alSum << endl;
os << "Total weight Paper:"
<< pSum << endl;
os << "Total weight Glass:"
<< gSum << endl;
os << "Total weight Cardboard:"
<< cSum << endl;
}
};
int main() {
vector<Trash*> bin;
// fillBin() still works, without changes, but
// different objects are prototyped:
fillBin("Trash.dat", bin);
// You could even iterate through
// a list of visitors!
PriceVisitor pv;
WeightVisitor wv;
vector<Trash*>::iterator it = bin.begin();
while(it != bin.end()) {
(*it)->accept(pv);
(*it)->accept(wv);
it++;
}
pv.total(out);
wv.total(out);
purge(bin);}
///:~
Note that the shape of main( ) has changed again.
Now there’s only a single Trash bin. The two Visitor objects
are accepted into every element in the sequence, and they perform their
operations. The visitors keep their own internal data to tally the total weights
and prices.
Finally, there’s no run-time type identification other
than the inevitable cast to Trash when pulling things out of the
sequence.
One way you can distinguish this solution from the double
dispatching solution described previously is to note that, in the double
dispatching solution, only one of the overloaded methods, add( ),
was overridden when each subclass was created, while here each one of the
overloaded visit( ) methods is overridden in every subclass of
Visitor.
There’s a lot more code here, and there’s definite
coupling between the Trash hierarchy and the Visitor hierarchy.
However, there’s also high cohesion within the respective sets of classes:
they each do only one thing (Trash describes trash, while Visitor
describes actions performed on Trash), which is an indicator of a
good design. Of course, in this case it works well only if you’re adding
new Visitors, but it gets in the way when you add new types of
Trash.
Low coupling between classes and high cohesion within a class
is definitely an important design goal. Applied mindlessly, though, it can
prevent you from achieving a more elegant design. It seems that some classes
inevitably have a certain intimacy with each other. These often occur in pairs
that could perhaps be called couplets, for
example, containers and iterators. The Trash-Visitor pair above appears
to be another such
couplet.
Various designs in this chapter attempt to remove RTTI, which
might give you the impression that it’s “considered harmful”
(the condemnation used for poor goto). This isn’t true; it is the
misuse of RTTI that is the problem. The reason our
designs removed RTTI is because the misapplication of that feature prevented
extensibility, which contravened the stated goal of
adding a new type to the system with as little impact on surrounding code as
possible. Since RTTI is often misused by having it look for every single type in
your system, it causes code to be non-extensible: when you add a new type, you
have to go hunting for all the code in which RTTI is used, and if you miss any
you won’t get help from the compiler.
However, RTTI doesn’t automatically create
non-extensible code. Let’s revisit the trash recycler once more. This
time, a new tool will be introduced, which I call a TypeMap. It inherits
from a map that holds a variant of type_info object as the key,
and vector<Trash*> as the value. The interface is simple: you call
addTrash( ) to add a new Trash pointer, and the map
class provides the rest of the interface. The keys represent the types
contained in the associated vector. The beauty of this design (suggested
by Larry O’Brien) is that the TypeMap dynamically adds a new
key-value pair whenever it encounters a new type, so whenever you add a new type
to the system (even if you add the new type at runtime), it adapts.
The example will again build on the structure of the
Trash types, and will use fillBin( ) to parse and insert the
values into the TypeMap. However, TypeMap is not a
vector<Trash*>, and so it must be adapted to work with
fillBin( ) by multiply inheriting from Fillable. In addition,
the Standard C++ type_info class is too restrictive to be used as a key,
so a kind of wrapper class TypeInfo is created, which simply extracts and
stores the type_info char* representation of the type (making the
assumption that, within the realm of a single compiler, this representation will
be unique for each type).
//: C10:DynaTrash.cpp
//{L} TrashPrototypeInit
//{L} fillBin Trash TrashStatics
// Using a map of vectors and RTTI
// to automatically sort Trash into
// vectors. This solution, despite the
// use of RTTI, is extensible.
#include "Trash.h"
#include "fillBin.h"
#include "sumValue.h"
#include "../purge.h"
#include <iostream>
#include <fstream>
#include <vector>
#include <map>
#include <typeinfo>
using namespace std;
ofstream out("DynaTrash.out");
// Must adapt from type_info in Standard C++,
// since type_info is too restrictive:
template<class T> // T should be a base class
class TypeInfo {
string id;
public:
TypeInfo(T* t) : id(typeid(*t).name()) {}
const string& name() { return id; }
friend bool operator<(const TypeInfo& lv,
const TypeInfo& rv){
return lv.id < rv.id;
}
};
class TypeMap :
public map<TypeInfo<Trash>, vector<Trash*> >,
public Fillable {
public:
// Satisfies the Fillable interface:
void addTrash(Trash* t) {
(*this)[TypeInfo<Trash>(t)].push_back(t);
}
~TypeMap() {
for(iterator it = begin(); it != end(); it++)
purge((*it).second);
}
};
int main() {
TypeMap bin;
fillBin("Trash.dat", bin); // Sorting happens
TypeMap::iterator it;
for(it = bin.begin(); it != bin.end(); it++)
sumValue((*it).second);}
///:~
TypeInfo is templatized because typeid( )
does not allow the use of void*, which would be the most general way to
solve the problem. So you are required to work with some specific class, but
this class should be the most base of all the classes in your hierarchy.
TypeInfo must define an operator< because a map needs it
to order its keys.
Although powerful, the definition for TypeMap is
simple; the addTrash( ) member function does most of the work. When
you add a new Trash pointer, the a TypeInfo<Trash> object
for that type is generated. This is used as a key to determine whether a
vector holding objects of that type is already present in the map.
If so, the Trash pointer is added to that vector. If not, the
TypeInfo object and a new vector are added as a key-value
pair.
An iterator to the map, when dereferenced, produces a pair
object where the key (TypeInfo) is the first
member, and the value (Vector<Trash*>) is the second
member. And that’s all there is to it.
The TypeMap takes advantage of the design of
fillBin( ), which doesn’t just try to fill a vector but
instead anything that implements the Fillable interface with its
addTrash( ) member function. Since TypeMap is multiply
inherited from Fillable, it can be used as an argument to
fillBin( ) like this:
fillBin("Trash.dat",
bin);
An interesting thing about this design is that even though it
wasn’t created to handle the sorting, fillBin( ) is performing
a sort every time it inserts a Trash pointer into bin. When the
Trash is thrown into bin it’s immediately sorted by
TypeMap’s internal sorting mechanism. Stepping through the
TypeMap and operating on each individual vector becomes a simple
matter, and uses ordinary STL syntax.
As you can see, adding a new type to the system won’t
affect this code at all, nor the code in TypeMap. This is certainly the
smallest solution to the problem, and arguably the most elegant as well. It does
rely heavily on RTTI, but notice that each key-value pair in the map is
looking for only one type. In addition, there’s no way you can
“forget” to add the proper code to this system when you add a new
type, since there isn’t any code you need to add, other than that which
supports the prototyping process (and you’ll find out right away if you
forget that).
Coming up with a design such as TrashVisitor.cpp that
contains a larger amount of code than the earlier designs can seem at first to
be counterproductive. It pays to notice what you’re trying to accomplish
with various designs. Design patterns in general strive to separate the
things that change from the things that stay the same. The “things
that change” can refer to many different kinds of changes. Perhaps the
change occurs because the program is placed into a new environment or because
something in the current environment changes (this could be: “The user
wants to add a new shape to the diagram currently on the screen”). Or, as
in this case, the change could be the evolution of the code body. While previous
versions of the trash-sorting example emphasized the addition of new
types of Trash to the system, TrashVisitor.cpp allows you
to easily add new functionality without disturbing the Trash
hierarchy. There’s more code in TrashVisitor.cpp, but adding new
functionality to Visitor is cheap. If this is something that happens a
lot, then it’s worth the extra effort and code to make it happen more
easily.
The discovery of the vector of change
is no trivial matter; it’s not something that an analyst can usually
detect before the program sees its initial design. The necessary information
will probably not appear until later phases in the project: sometimes only at
the design or implementation phases do you discover a deeper or more subtle need
in your system. In the case of adding new types (which was the focus of most of
the “recycle” examples) you might realize that you need a particular
inheritance hierarchy only when you are in the maintenance phase and you begin
extending the system!
One of the most important things that you’ll learn by
studying design patterns seems to be an about-face from what has been promoted
so far in this book. That is: “OOP is all about polymorphism.” This
statement can produce the “two-year-old with a hammer” syndrome
(everything looks like a nail). Put another way, it’s hard enough to
“get” polymorphism, and once you do, you try to cast all your
designs into that one particular mold.
What design patterns say is that OOP isn’t just about
polymorphism. It’s about “separating the things that change from the
things that stay the same.” Polymorphism is an
especially important way to do this, and it turns out to be helpful if the
programming language directly supports polymorphism (so you don’t have to
wire it in yourself, which would tend to make it prohibitively expensive). But
design patterns in general show other ways to accomplish the basic goal,
and once your eyes have been opened to this you will begin to search for more
creative designs.
Since the Design Patterns book came out and made such
an impact, people have been searching for other patterns. You can expect to see
more of these appear as time goes on. Here are some sites recommended by Jim
Coplien, of C++ fame (http://www.bell-labs.com/~cope), who is one of the
main proponents of the patterns movement:
http://st-www.cs.uiuc.edu/users/patterns
http://c2.com/cgi/wiki
http://c2.com/ppr
http://www.bell-labs.com/people/cope/Patterns/Process/index.html
http://www.bell-labs.com/cgi-user/OrgPatterns/OrgPatterns
http://st-www.cs.uiuc.edu/cgi-bin/wikic/wikic
http://www.cs.wustl.edu/~schmidt/patterns.html
http://www.espinc.com/patterns/overview.html
Also note there has been a yearly conference on design
patterns, called PLOP, that produces a published proceedings. The third one of
these proceedings came out in late 1997 (all published by
Addison-Wesley).
[25]
Conveniently, the examples are in C++.
[26]James O.
Coplien, Advanced C++ Programming Styles and Idioms, Addison-Wesley,
1992.